GadgetInspector源码分析
【推荐学习】暗月渗透测试培训 十多年渗透经验,体系化培训渗透测试 、高效学习渗透测试,欢迎添加微信好友aptimeok 咨询。
前言
GadgetInspector是2018年blackhatusa上面发布的一个自动化链子挖掘工具,通过asm的方法来对字节码进行静态的分析,以污点传播的方式来挖掘可能存在的链子,考虑到项目大多获取的都是war,jar包的形式
原始的GadgetInspector是不能用来挖掘漏洞的,只能找出source(入口点)→sink链
在学习整个项目前,需要读者有asm的基础和字节码的基础,否则比较难看懂
例子
看完了整个项目,我认为最主要难理解的就是在于局部变量表和操作数栈的理解,所以这里先用一个简单的例子来帮助学习理解
test.java
package sample;
public class test {
public static void main(String[] args) {
public test(){
}
test test = new test();
method2(test.method1("hhh"));
}
public String method1(String arg){
return arg;
}
public static String method2(String arg){
String a = "v1f18";
return a+arg;
}
}
然后结合字节码来看
构造方法

与其对应的局部变量表和栈
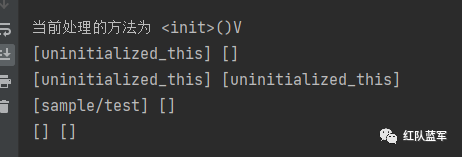
因为在处理构造方法的时候,对象没有实例化,所以这里的uninitialized_this指代的是一个内存地址,所以初始化的时候就为[uninitialized_this] [] 然后遇到aload0,加载地址到操作数栈中,然后调用invokespecial执行方法,对象就初始化了,最后return,清空
method1
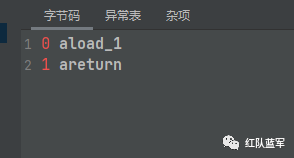
对应的表和栈
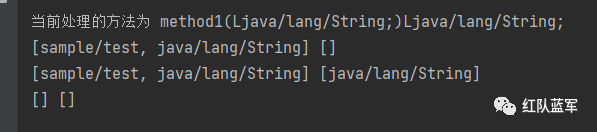
因为不是静态的方法,所以0参为this,即test,然后放入参数为string,执行指令aload_1,将string的数据放入操作数栈中,然后return
method2
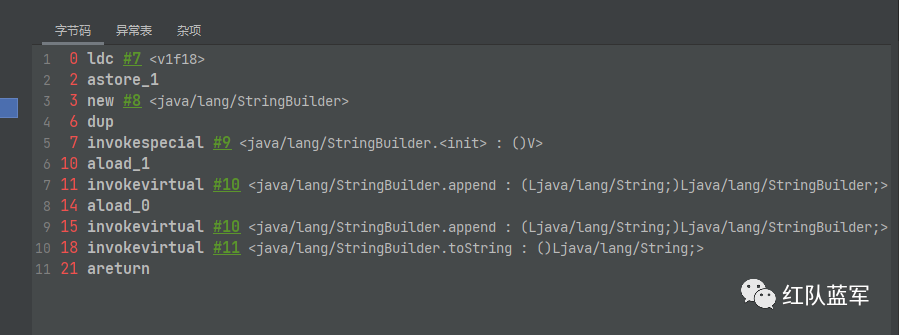
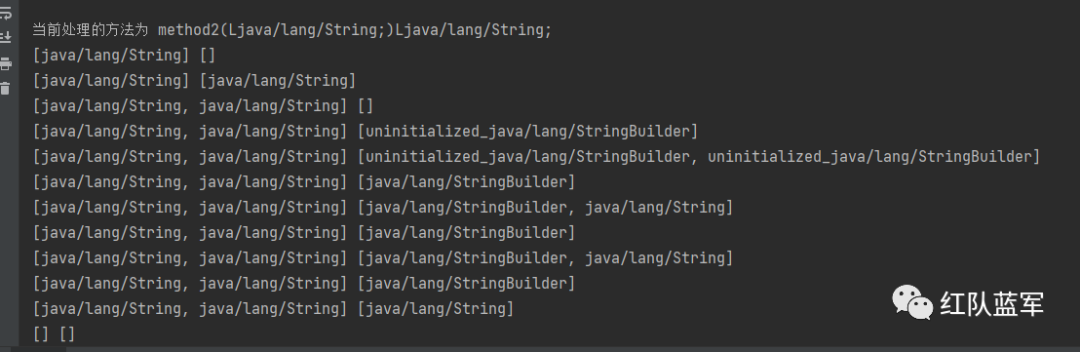
因为method2是静态方法,所以0参即为参数,初始化为[java/lang/String] []
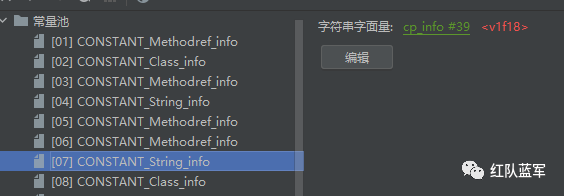
遇到的第一个影响操作数栈的指令ldc #7将常量池中的7号元素加载到操作数栈中,为v1f18
即变成了[java/lang/String] [java/lang/String]
astore_1将栈顶的元素加入到变量表的1号位中,[java/lang/String, java/lang/String] []
new #8将常量池的8号元素创建到栈中,[java/lang/String, java/lang/String] [uninitialized_java/lang/StringBuilder]
dup赋值栈顶元素,放入栈顶[java/lang/String, java/lang/String] [uninitialized_java/lang/StringBuilder, uninitialized_java/lang/StringBuilder]
invokespecial #9执行StringBuilder的构造方法初始化,消耗掉栈顶的元素,[java/lang/String, java/lang/String] [java/lang/StringBuilder]
aload_1 加载变量表的一号元素到栈中,[java/lang/String, java/lang/String] [java/lang/StringBuilder, java/lang/String]
invokevirtual #10调用append方法,消耗掉栈顶元素[java/lang/String, java/lang/String] [java/lang/StringBuilder]
aload_0 加载表的0号元素[java/lang/String, java/lang/String] [java/lang/StringBuilder, java/lang/String]
invokevirtual #10 调用append继续消耗[java/lang/String, java/lang/String] [java/lang/StringBuilder]
invokevirtual #11 调用toString消耗掉最后一个元素,[java/lang/String, java/lang/String] [java/lang/String]
areturn清空
main
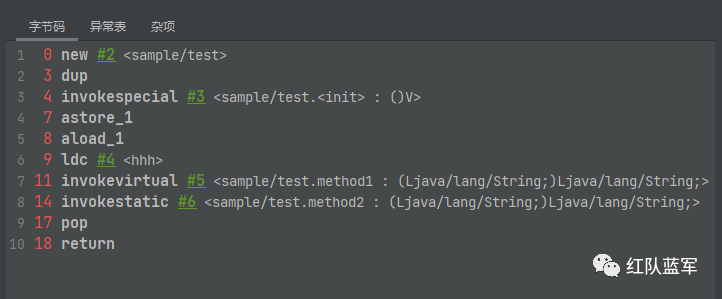
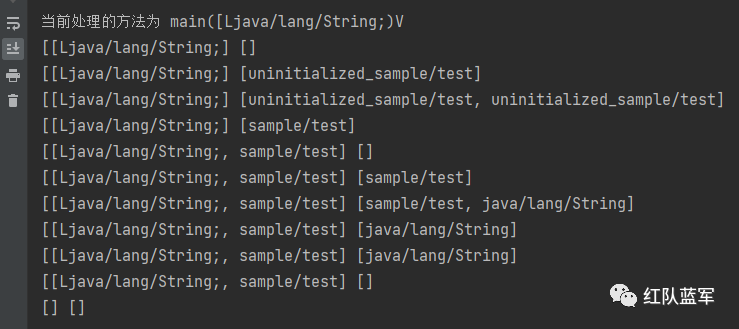
main方法为静态方法,参数为数组,这里用[Ljava/lang/String来表示,所以初始化为[[Ljava/lang/String;] []
new #2将常量池的2号元素放入栈中[[Ljava/lang/String;] [uninitialized_sample/test]
dup 复制栈顶元素[[Ljava/lang/String;] [uninitialized_sample/test, uninitialized_sample/test]
invokespecial #3 消耗元素[[Ljava/lang/String;] [sample/test]
astore_1 放入变量表[[Ljava/lang/String;, sample/test] []
aload_1 加载数据到栈[[Ljava/lang/String;, sample/test] [sample/test]
ldc #4 继续放数据到栈 [[Ljava/lang/String;, sample/test] [sample/test, java/lang/String]
invokevirtual 调用方法消耗元素,这里因为method1是由返回值的,所以把返回值放入栈顶 [[Ljava/lang/String;, sample/test] [java/lang/String]
invokestatic 调用静态方法,消耗元素,并且返回数据到栈顶,[[Ljava/lang/String;, sample/test] [java/lang/String]
pop 弹出栈顶元素[[Ljava/lang/String;, sample/test] []
return 清空
通过这个例子,可以稍微理解一些操作数栈的局部变量表之间的关系了,我认为gi的核心代码在于对参数与返回值之间的解析,所以理解这两者是非常主要的
因为在看整个项目的时候只需要看我们自己写的代码就行了,其他的不看,所以我这里修改了getAllClasses方法的代码,可以不改
比如我现在的测试项目包的名称就是com.example.gadgetinspectortest
那么我就需要修改成以下的样子:
public Collection<ClassResource> getAllClasses() throws IOException {
Collection<ClassResource> result = new ArrayList<>();
if (ConfigHelper.onlyJDK)
return result;
for (ClassPath.ClassInfo classInfo : ClassPath.from(classLoader).getAllClasses()) {
if (classInfo.getPackageName().equals("com.example.gadgetinspectortest")){
result.add(new ClassLoaderClassResource(classLoader, classInfo.getResourceName()));
}
}
return result;
}
getRuntimeClasses直接不用,以学习为主
入口类GadgetInspector
GadgetInspector是整个项目的启动类,在这个类中,包含了对参数的解析,字节码分析,数据保存的功能
查看静态代码块
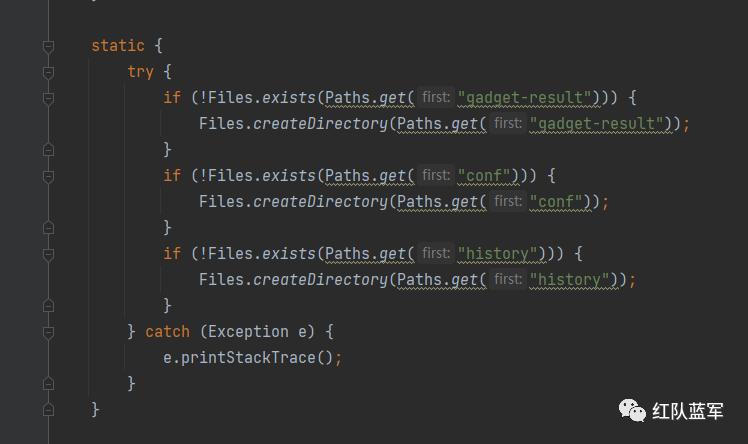
这里就是创建一些目录用来保存文件
进入main方法
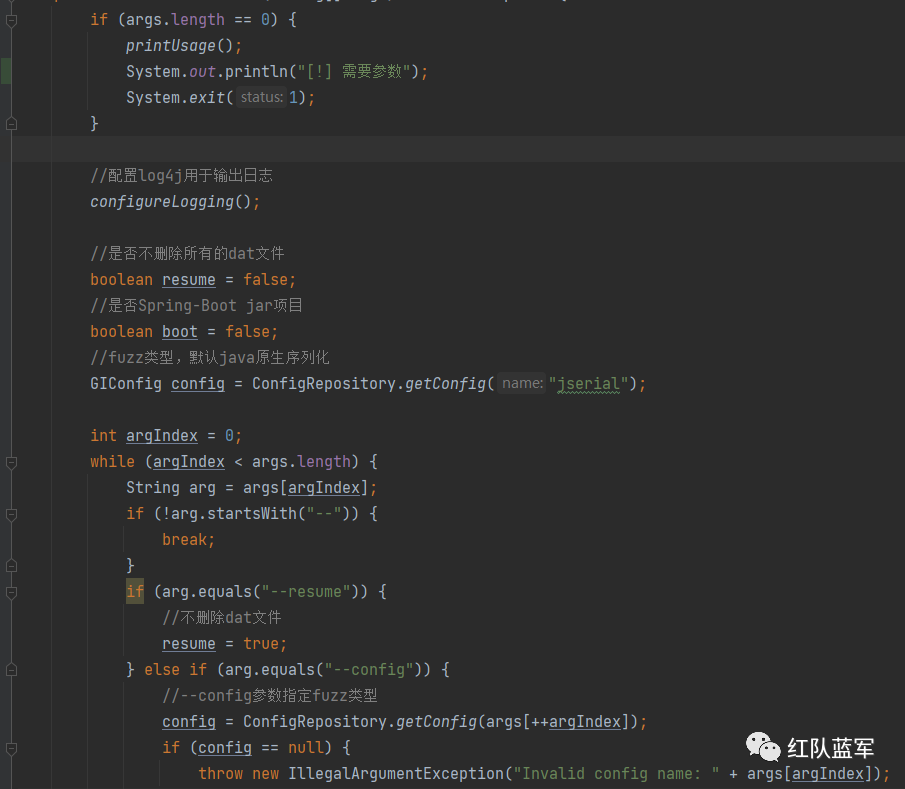
这里先判断传入的参数是否为空,然后处理参数
initJarData

这里把需要处理的jar文件当作参数传入该方法
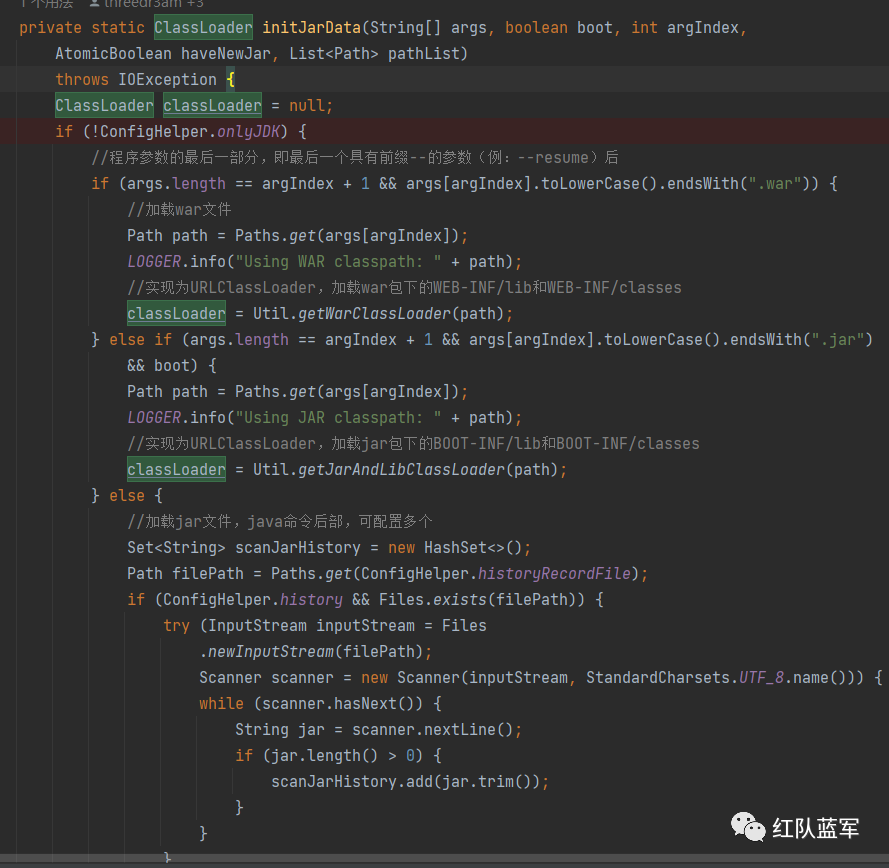
因为没有指定任何参数,所以直接进入Util.getJarClassLoader方法
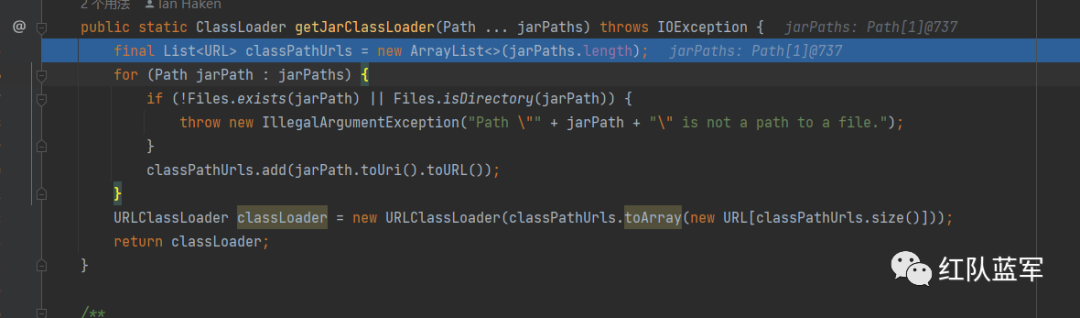
这里就获取了测试jar文件中的classLoader
回到main方法
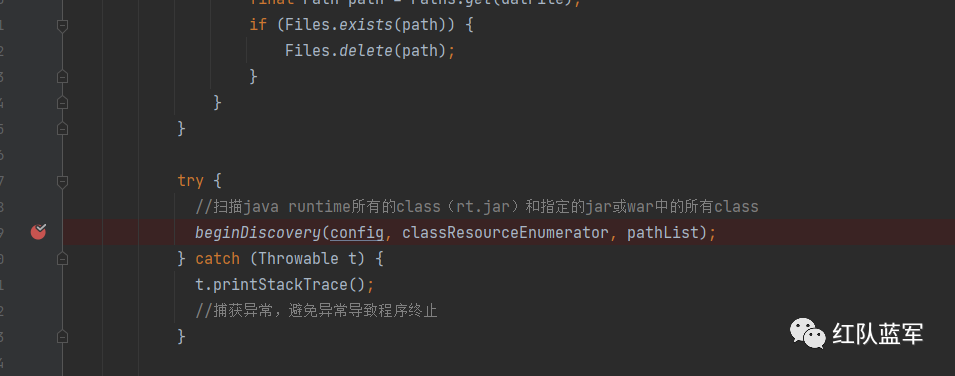
进入beginDiscovery方法,最重要的一个方法
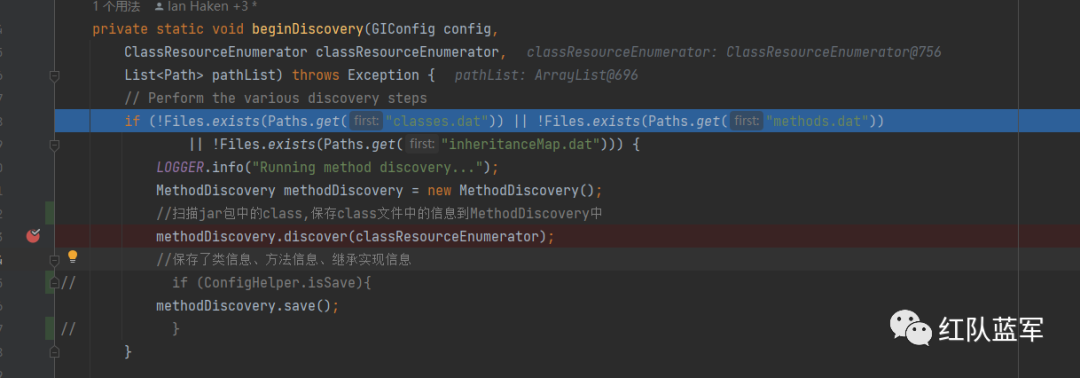
MethodDiscovery
在MethodDiscovery类中,扫描jar,war中的所有.class文件信息,并且保存至文件中,为后续的调用提供数据
进入methodDiscovery.discover方法,将之前的测试jar的classloader参数传入
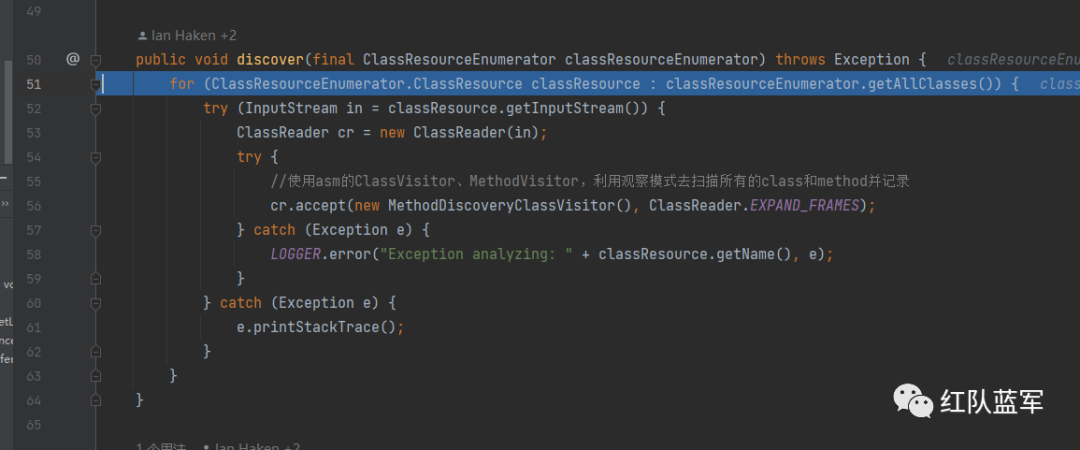
这里要注意下getAllClasses方法
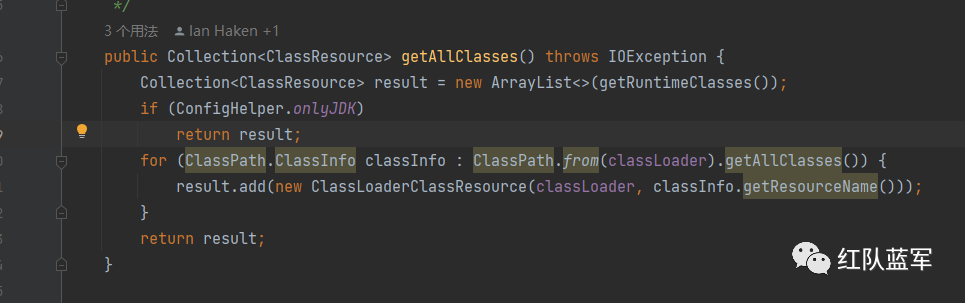
这里的getAllClasses会把rt.jar加载到classloader中去,对调试的过程有影响,我这里就直接不要rt.jar了,后续二开的时候可以根据需求选择,直接把list中的getRuntimeClasses方法删去即可
这里简单说一下怎么加载的rt.jar
首先获取String.class所在的文件目录url,判断是否为JarURLConnection,如果是的话获取目录,即rt.jar
最后创建一个classloader来加载它,jdk9以上的情况不考虑
回到discover方法
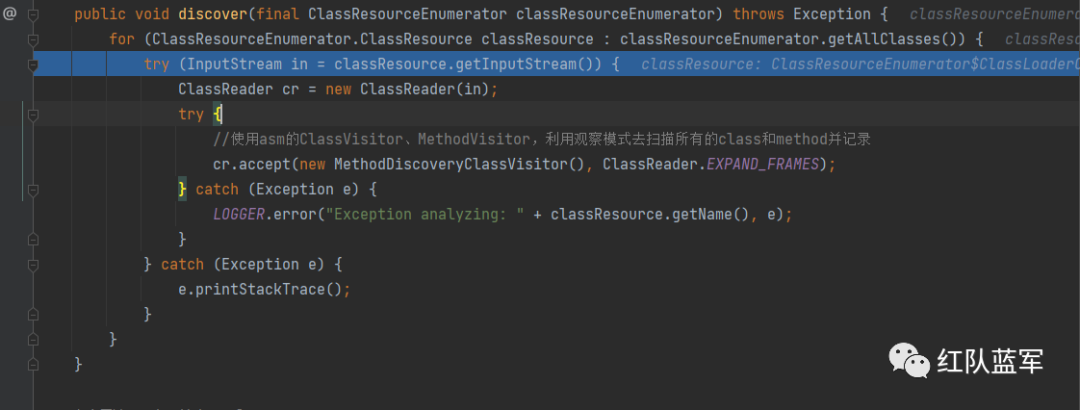
循环每一个class文件的二进制流,创建ClassReader来具体分析class文件
因为asm是观察者模式的具体实现,所以这里使用MethodDiscoveryClassVisitor这个类来扫描所有的class和方法
看一下MethodDiscoveryClassVisitor都有什么
MethodDiscoveryClassVisitor是MethodDiscovery的内部类,重点看visitMethod和visitEnd方法
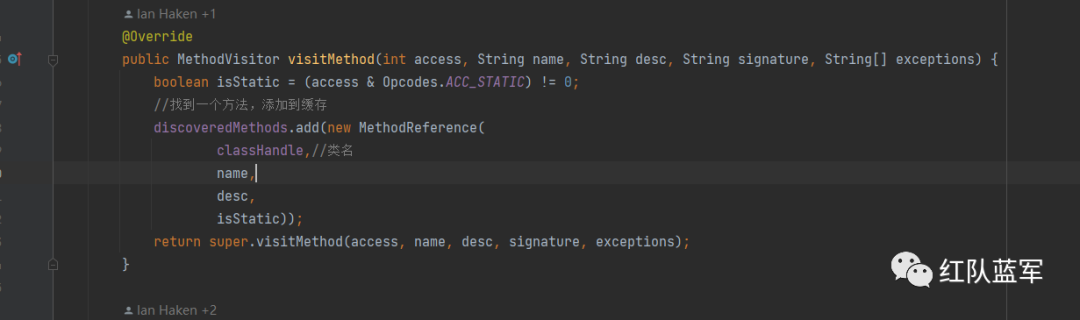
只要找到了一个方法就会被加入到discoveredMethods中
每一个方法遍历完成加入到discoveredClasses中
回到beginDiscovery方法,当所有class被扫描一遍之后就会通过save来保存
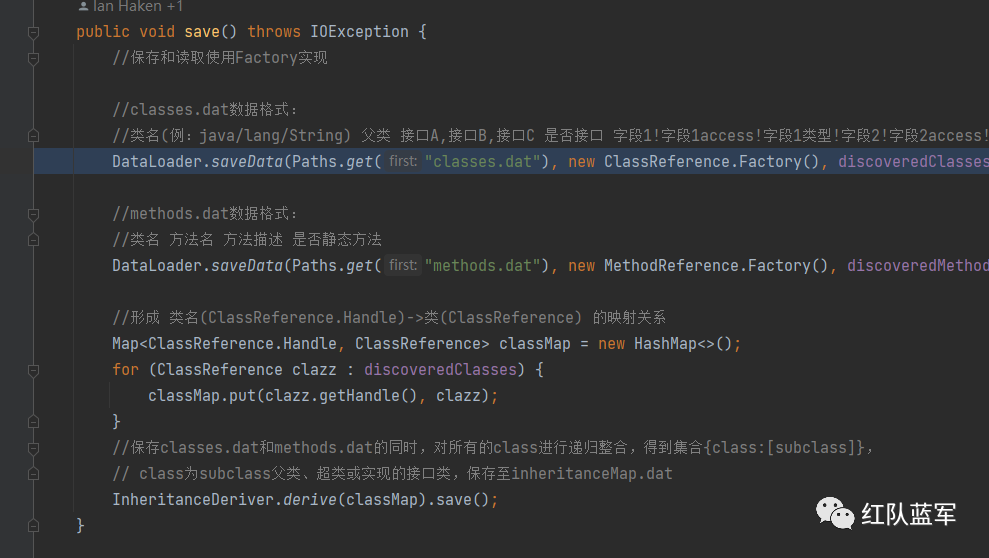
到目前为止获取到了classes.data(所有的class) ,methods.dat(所有的方法),以及父子类/接口关系的inheritanceMap.dat
PassthroughDiscovery
在PassthroughDiscovery类中,就是gi最核心的代码,先对所有方法做循环处理,找出在其他方法内部被调用的方法,接着使用逆拓扑的方式进行排序,得到一个列表,后续的所有操作都需要用到这个列表,最后在calculatePassthroughDataflow中计算参数和返回值的关系
执行passthroughDiscovery.discover
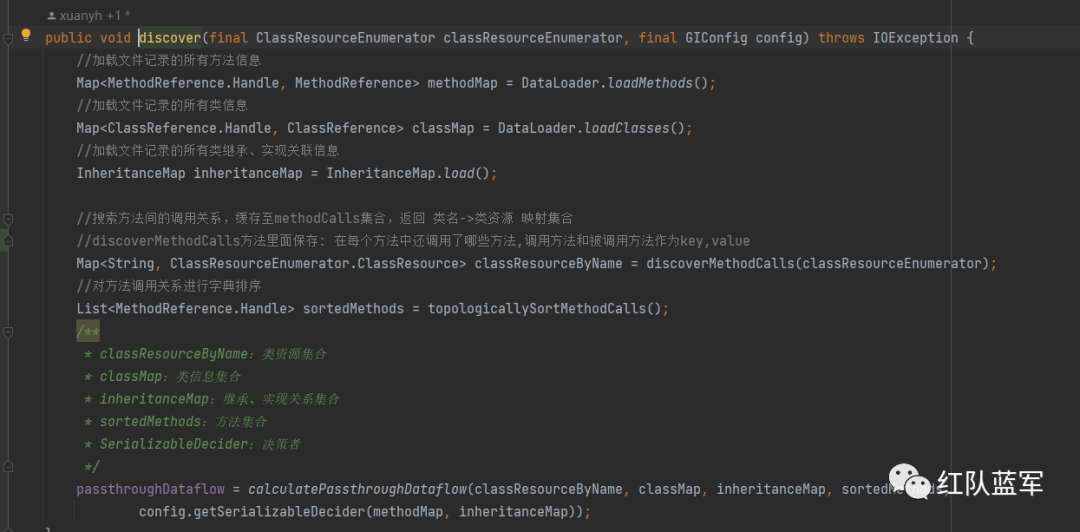
下面就是比较难理解的地方了,这里先用一个例子来展示discover到底在干嘛
public void main(String args) throws IOException {
String cmd = new A().method1(args);
new B().method2(cmd);
}
class A {
public String method1(String param) {
return param;
}
}
class B {
public void method2(String param) throws IOException {
new C().method3(param);
}
}
class C {
public void method3(String param) throws IOException {
Runtime.getRuntime().exec(param);
}
}
在这个例子中,当A调用method1方法的时候,传入的参数和返回的值是有关系的所以: A#method1 → 1 (后面的1表示参数与返回值的关系,1表示有,0表示没有)
当B调用method2的时候,传入的参数和返回值没有办法一眼看出,所以需要提前知道C中的method3做了什么,所以: B#method2 → 1
当C调用method3的时候,和B的情况一样,需要提前查看在方法内调用的方法得知参数和返回值之间的关系
C#method3 → 1
通过人为的正向分析,从A调用传入的参数一直到exec方法都没有过滤,但是从机器的角度来时不行的,没有办法提前知道方法和参数的关系,所以这里使用了DTS(一种逆拓扑图的方式)从C开始反向的查看B的关系,最后到A
先看一下是怎么收集方法与方法之间的关系的
discoverMethodCalls方法
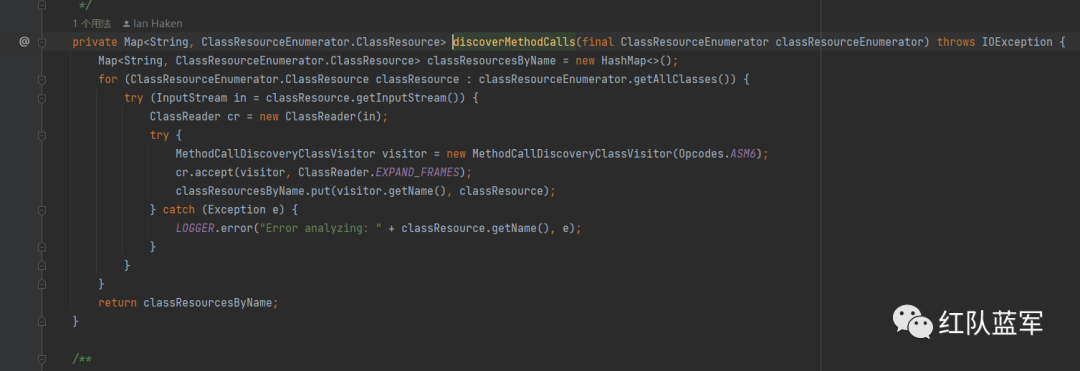
还是一样的,通过classLoader来获取class,然后循环class使用ClassReader分析
这里使用了MethodCallDiscoveryClassVisitor作为观察者
MethodCallDiscoveryClassVisitor的具体方法
@Override
public void visit(int version, int access, String name, String signature,
String superName, String[] interfaces) {
super.visit(version, access, name, signature, superName, interfaces);
if (this.name != null) {
throw new IllegalStateException("ClassVisitor already visited a class!");
}
this.name = name;
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc,
String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, desc, signature, exceptions);
//在visit每个method的时候,创建MethodVisitor对method进行观察
MethodCallDiscoveryMethodVisitor modelGeneratorMethodVisitor = new MethodCallDiscoveryMethodVisitor(
api, mv, this.name, name, desc);
return new JSRInlinerAdapter(modelGeneratorMethodVisitor, access, name, desc, signature, exceptions);
}
@Override
public void visitEnd() {
super.visitEnd();
}
按照以上的调用顺,当执行到visitMethod的时候,创建了MethodCallDiscoveryMethodVisitor类进一步来观察方法
MethodCallDiscoveryMethodVisitor包含以下的方法
public MethodCallDiscoveryMethodVisitor(final int api, final MethodVisitor mv,
final String owner, String name, String desc) {
super(api, mv);
//创建calledMethod收集调用到的method,最后形成集合{{sourceClass,sourceMethod}:[{targetClass,targetMethod}]}
this.calledMethods = new HashSet<>();
methodCalls.put(new MethodReference.Handle(new ClassReference.Handle(owner), name, desc), calledMethods);
}
@Override
public void visitMethodInsn(int opcode, String owner, String name, String desc, boolean itf) {
calledMethods.add(new MethodReference.Handle(new ClassReference.Handle(owner), name, desc));
super.visitMethodInsn(opcode, owner, name, desc, itf);
}
visitMethodInsn的作用就是当方法调用其他方法的时候会触发,正好对应上面的分析
通过calledMethods.add(new MethodReference.Handle(new ClassReference.Handle(owner), name, desc));来添加到calledMethods中
那么实现DTS的代码就在topologicallySortMethodCalls方法中
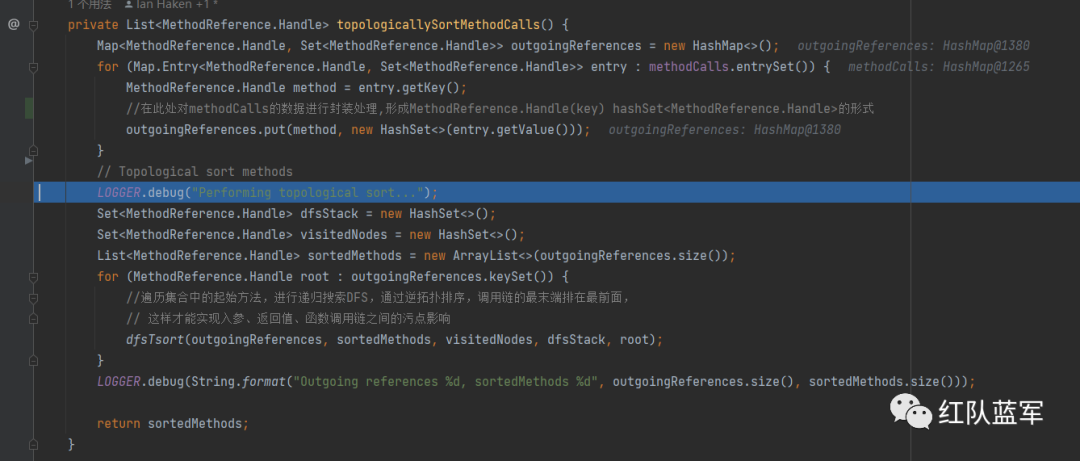
先对methodCalls的数据进行封装处理,形成MethodReference.Handle(key) hashSet<MethodReference.Handle>(value)的形式
进入dfsTsort方法
参数的大致分析
* outgoingReferences 对应整理的hashSet
* sortedMethods 排序用的List
* visitedNod 猜测应该是递归的时候需要一个节点(即已经做过测试了的方法)来防止死循环
* stack 模拟的栈
* node 当前测试的方法
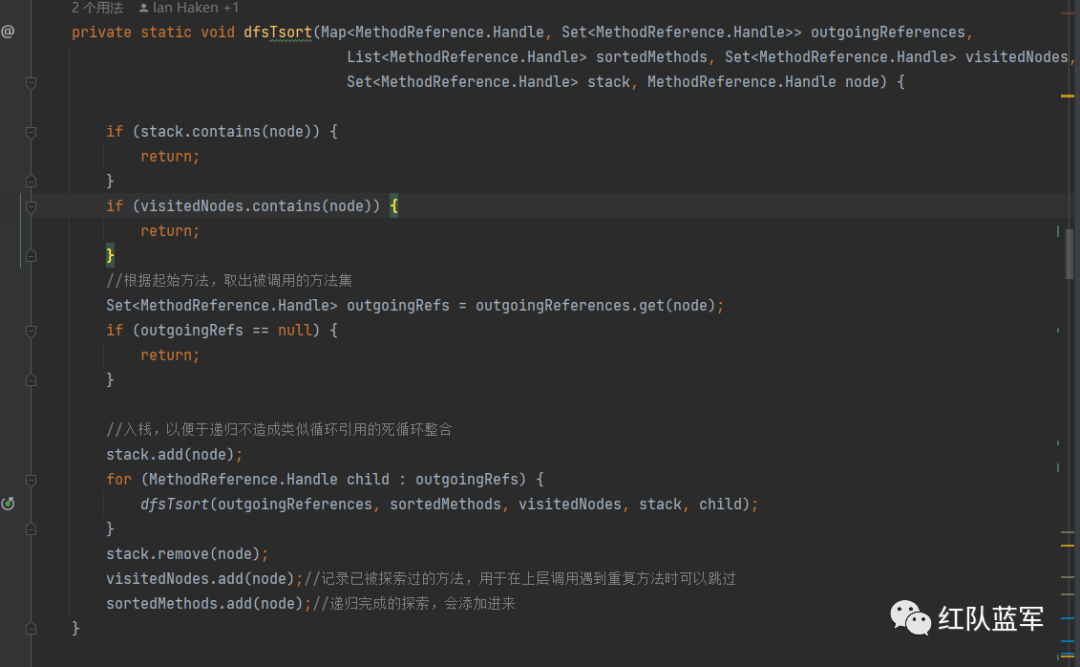
通过递归的方式来将对应包装的类名,方法名和返回值的对象进行排序,然后返回sortedMethods
然后就获得了8个已经排序好的方法
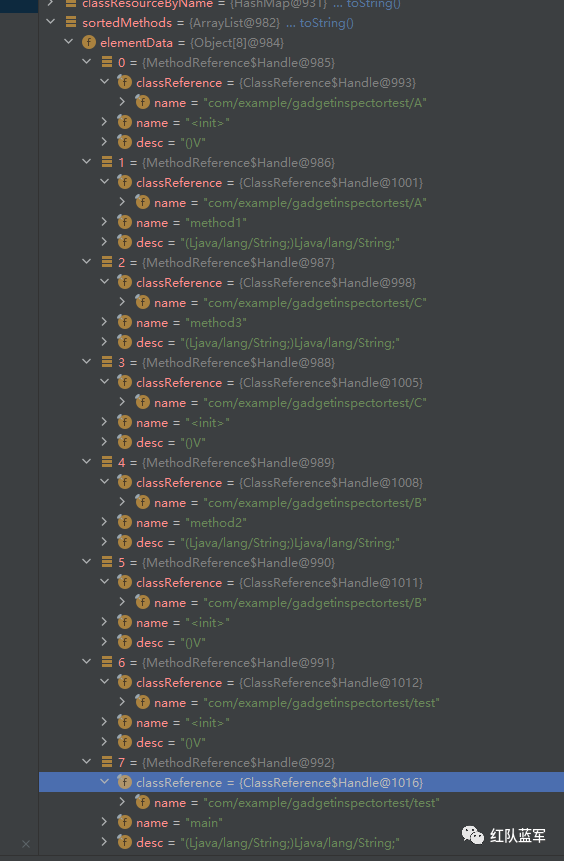
下一步就是进入calculatePassthroughDataflow来计算返回值和参数之间的关系
在分析这个方法之前先来解释以下
因为是通过asm来分析参数和返回值之间的关系,所以需要对asm的一些方法来做一个了解,先看上面的8个方法,第一个方法是A类的无参构造方法,下面是对应的字节码指令:
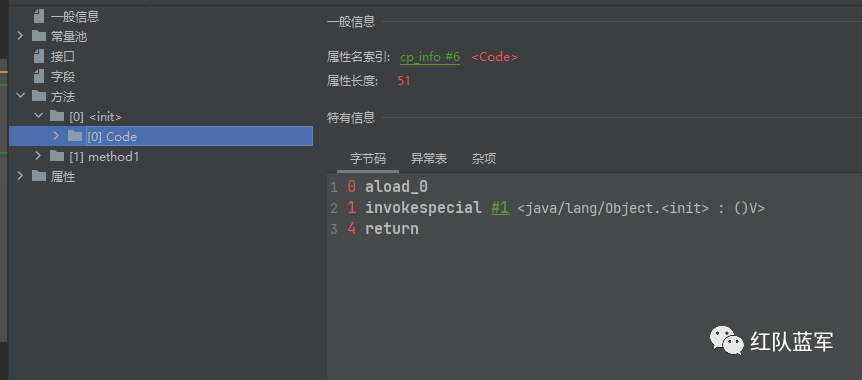
第一个指令是aload,对应TaintTrackingMethodVisitor的visitVarInsn方法
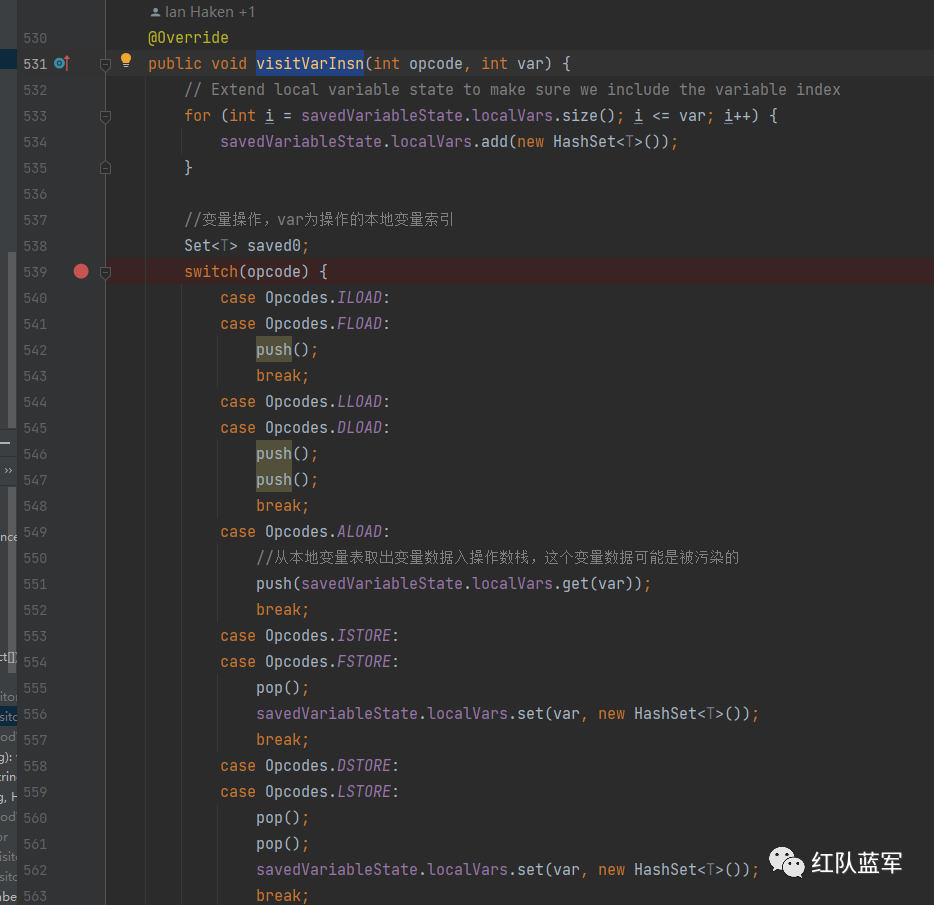
这里其实也有其他的字节码指令
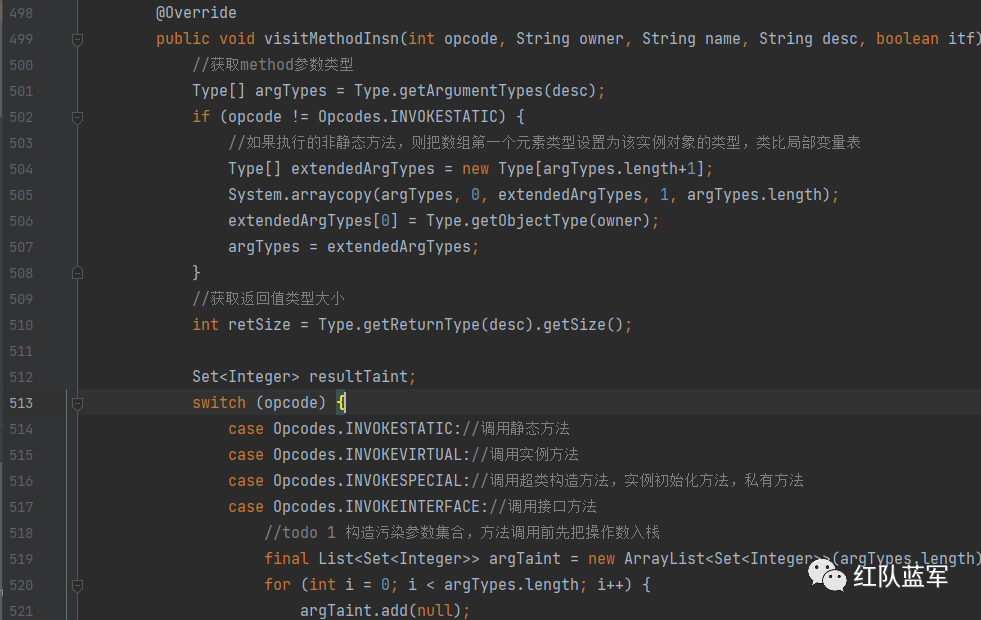
然后再看invokespecial对应的PassthroughDataflowMethodVisitor#visitMethodInsn
return对应的visitInsn
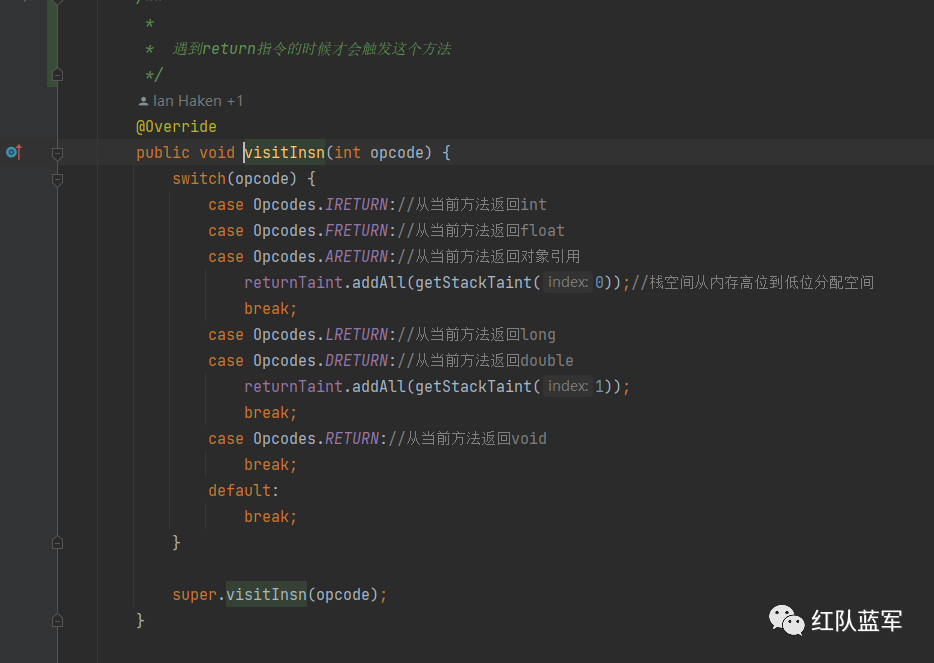
进入calculatePassthroughDataflow
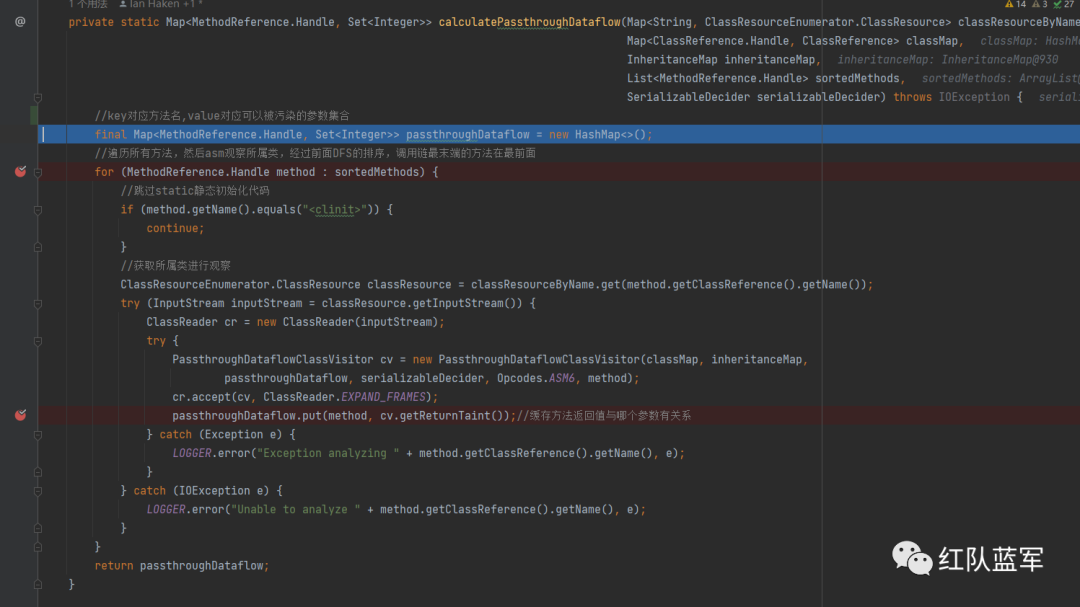
创建一个方法名和参数列表的变量passthroughDataflow
循环sortedMethods
因为静态代码块没有办法判断参数和返回之间的关系,所以直接跳过,其实这个也是gi不足的地方
读取class文件的二进制流之后交给ClassReader来分析
然后进入PassthroughDataflowClassVisitor的visitMethod,因为重写了该方法,即需要一个详细分析method的子类
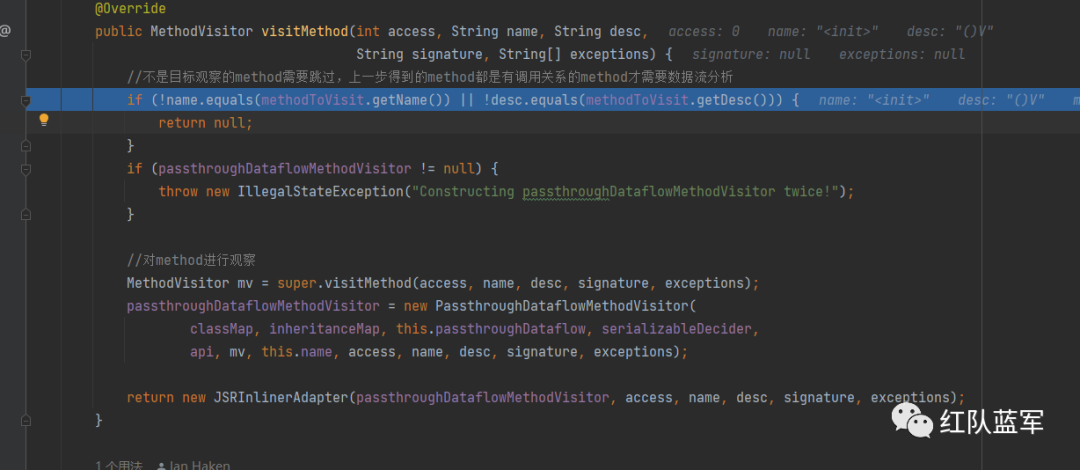
封装了PassthroughDataflowMethodVisitor到JSRInlinerAdapter
然后就是对无参构造方法里面的分析了
方法分析的流程
visitCode → visit* → visitEnd
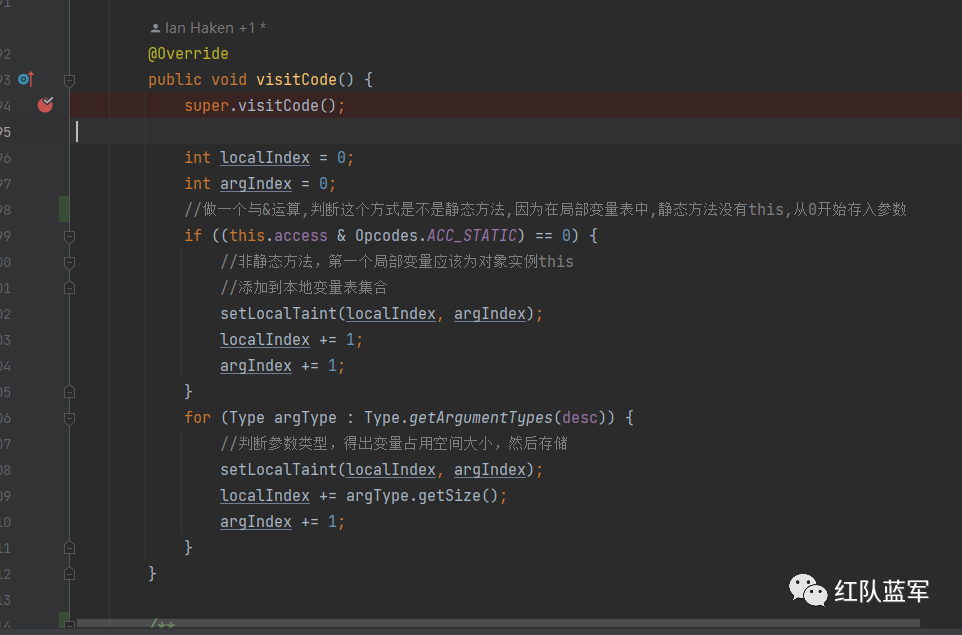
首先判断该方法是不是静态方法(因为静态方法,在局部变量表中不存在this这个0参)
我们这里是构造方法,所以将模拟局部变量表的变量savedVariableState.localVars+1
然后再判断参数的大小,引用类型和long,double占两个位置
然后进入visitVarInsn
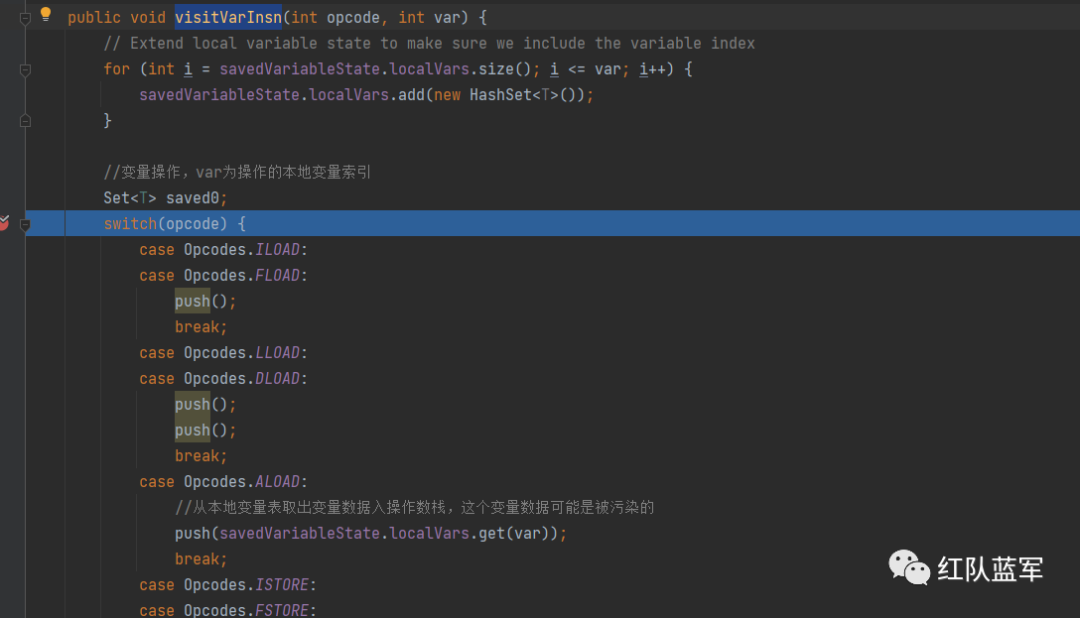
因为aload的作用就是将局部变量表中的数据添加到操作数栈里面
然后模拟操作数栈和局部变量表的两个参数如下:

接下来就进入关于return指令的方法了
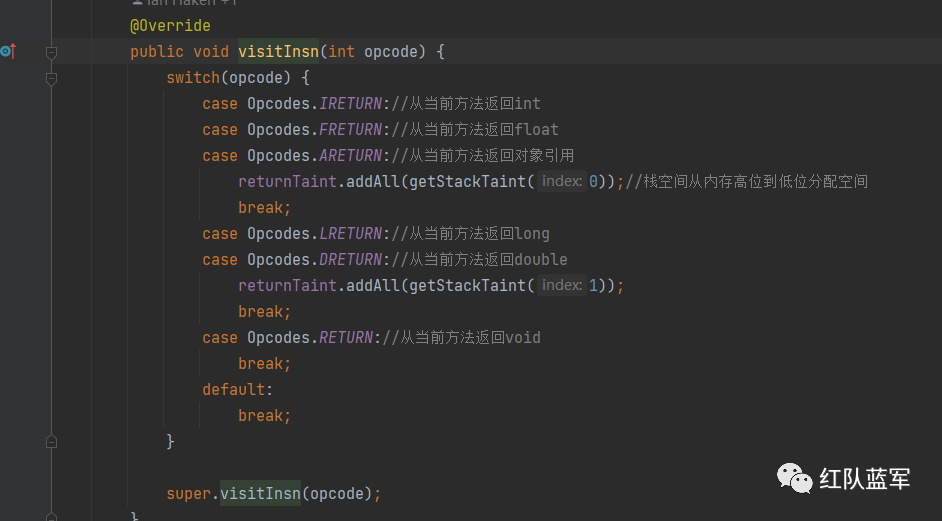
因为返回值为void,所以直接break了
然后下一个是A的method1方法
和上面不一样的就是返回值,将返回值放入returnTaint中
然后passthroughDataflow.put(method, cv.getReturnTaint())
将方法和对应的返回值对应
下面的C的method3和无参构造和上面一样,然后循环到B.method2的时候,就需要分析了,因为再method2中调用了C.method3
method2对应的字节码指令如下
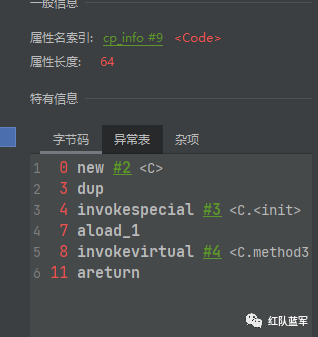
new dup这些先不关注
这里和之前不太一样,再分析C类的方法前,需要将method2的参数和返回值做一个分析,也就是需要把参数放入操作数栈中,然后再去分析C
将C的构造方法分析:
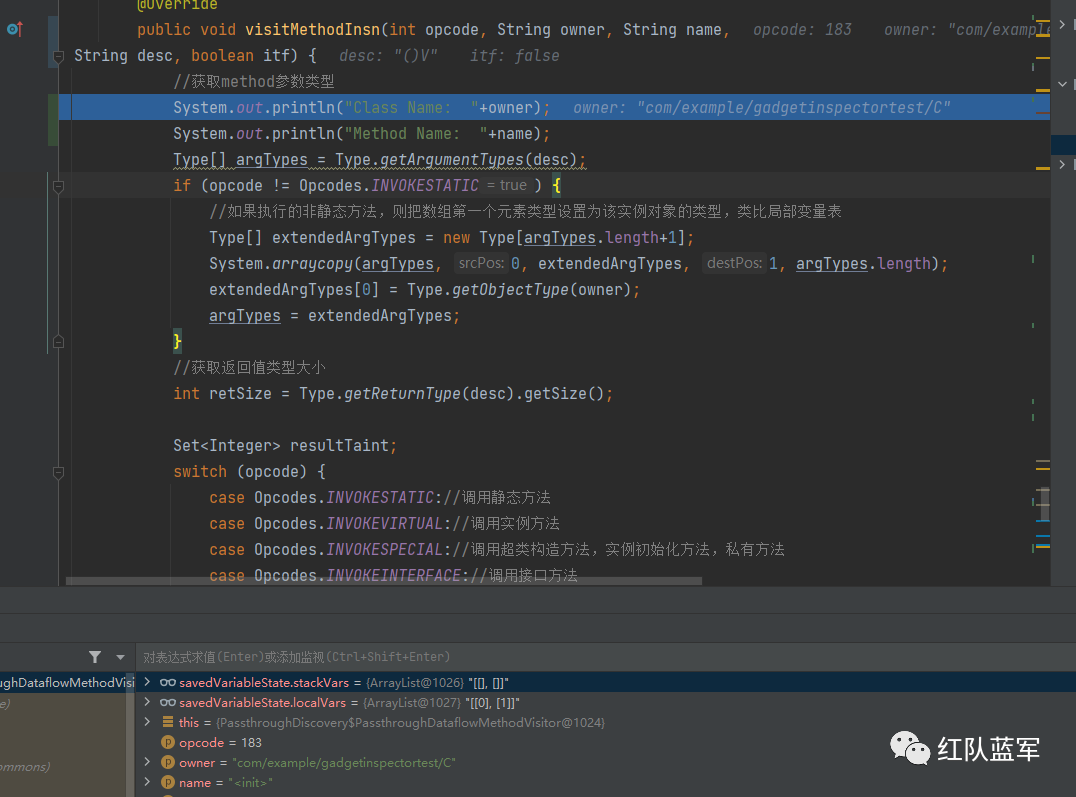
可以看见操作数栈和局部变量表的内容是已经存在数据了,后面就和前面分析一样,然后直接看method3是怎么执行的
根据字节码的信息,知道需要先执行对应aload的方法,也就是visitVarInsn,其实就是把可能存在污点的参数放入操作数栈中,变成如下的形式

然后再执行visitMethodInsn
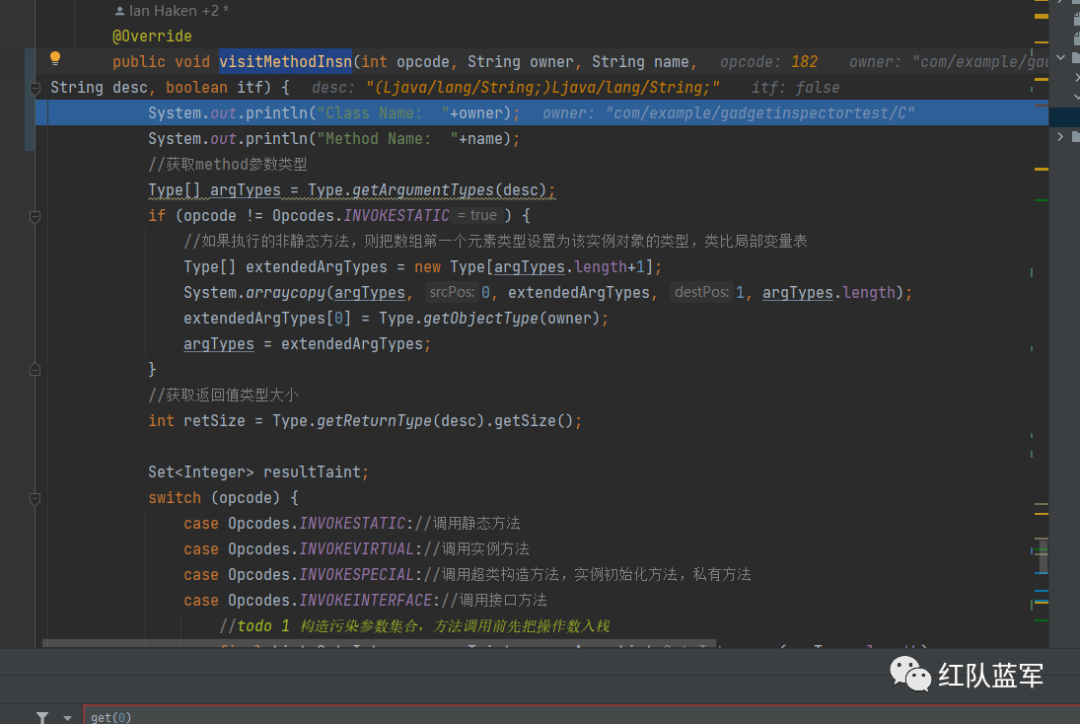
下面的代码就是再构造一个被调用方法的操作数栈和局部变量表
Type[] argTypes = Type.getArgumentTypes(desc);
if (opcode != Opcodes.INVOKESTATIC) {
//如果执行的非静态方法,则把数组第一个元素类型设置为该实例对象的类型,类比局部变量表
Type[] extendedArgTypes = new Type[argTypes.length+1];
System.arraycopy(argTypes, 0, extendedArgTypes, 1, argTypes.length);
extendedArgTypes[0] = Type.getObjectType(owner);
argTypes = extendedArgTypes;
}
//获取返回值类型大小
int retSize = Type.getReturnType(desc).getSize();
Set<Integer> resultTaint;
switch (opcode) {
case Opcodes.INVOKESTATIC://调用静态方法
case Opcodes.INVOKEVIRTUAL://调用实例方法
case Opcodes.INVOKESPECIAL://调用超类构造方法,实例初始化方法,私有方法
case Opcodes.INVOKEINTERFACE://调用接口方法
//todo 1 构造污染参数集合,方法调用前先把操作数入栈
final List<Set<Integer>> argTaint = new ArrayList<Set<Integer>>(argTypes.length);
for (int i = 0; i < argTypes.length; i++) {
argTaint.add(null);
}
int stackIndex = 0;
for (int i = 0; i < argTypes.length; i++) {
Type argType = argTypes[i];
if (argType.getSize() > 0) {
//根据参数类型大小,从栈顶获取入参,参数入栈是从左到右的
argTaint.set(argTypes.length - 1 - i, getStackTaint(stackIndex + argType.getSize() - 1));
}
stackIndex += argType.getSize();
}
然后转到passthroughDataflow.get(new MethodReference.Handle(new ClassReference.Handle(owner), name, desc));
这里就是为什么需要使用逆拓扑排序了,如果method2放在method3的前面分析的话,这里的返回肯定为空,造成漏报
这里返回的结果就是之前已经分析过的返回值和方法之间的关系(map)
resultTaint.addAll(argTaint.get(passthroughDataflowArg));
argTaint.get(passthroughDataflowArg)其实就是在做一个被调用方法的返回值与调用方法的返回值之间的一个比较,比如我method2返回的是String,我method3返回的也是String,所以相同,添加到resultTaint中
后面的areturn指令就不分析了
然后再执行到main这个方法,对应的字节码指令如下:
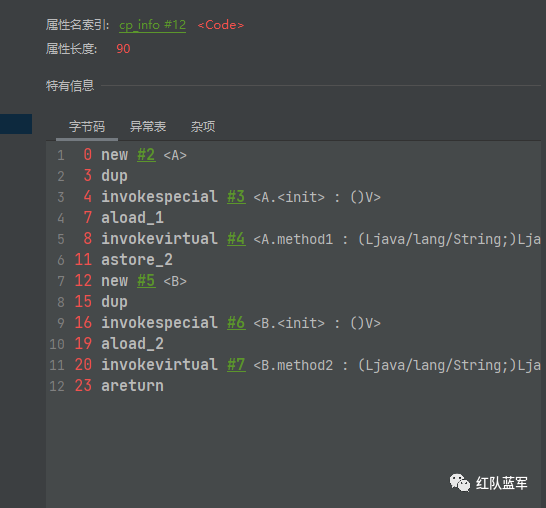
和上面的B.method2的执行比较相似,下面的执行过程是和分析有关的,之间还是存在其他方法的调用,不过对于参数的污染没啥关系
-
先执行visitCode存储入参到本地变量表(main的) -
执行visitMethodInsn,这里处理的方法是A的构造函数,判断是否与污点参数有关(很明显没关系) -
执行visitVarInsn,参数入栈 -
执行visitMethodInsn,开始分析A.method1是否存在污染(可能存在污染,所以将参数放在栈顶) -
执行visitVarInsn,把刚才放在栈顶的数据,放到变量表中 -
执行visitMethodInsn,这里处理的是B的构造方法,跳过 -
执行visitVarInsn,将参数放到操作数栈中 -
执行visitMethodInsn,这里处理B.method2,继续将可能污染的参数放到栈顶上去 -
最后执行visitInsn,将之前处理的方法和参数值对于的map放入returnTaint中
到这里就结束了,然后执行save方法,保存数据
CallGraphDiscovery
CallGraphDiscovery类,进行跟深层次的处理,调用者和被调用者的参数关系以及返回值
回到beginDiscovery,进入callGraphDiscovery.discover
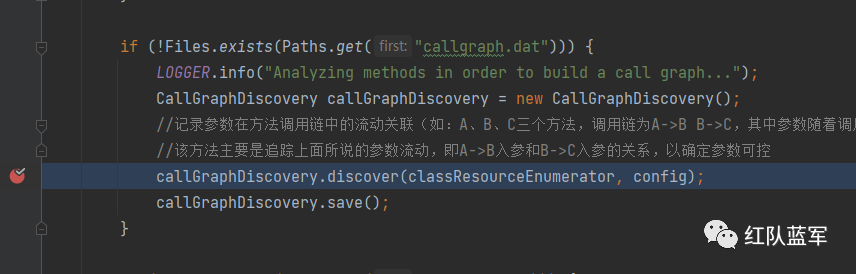
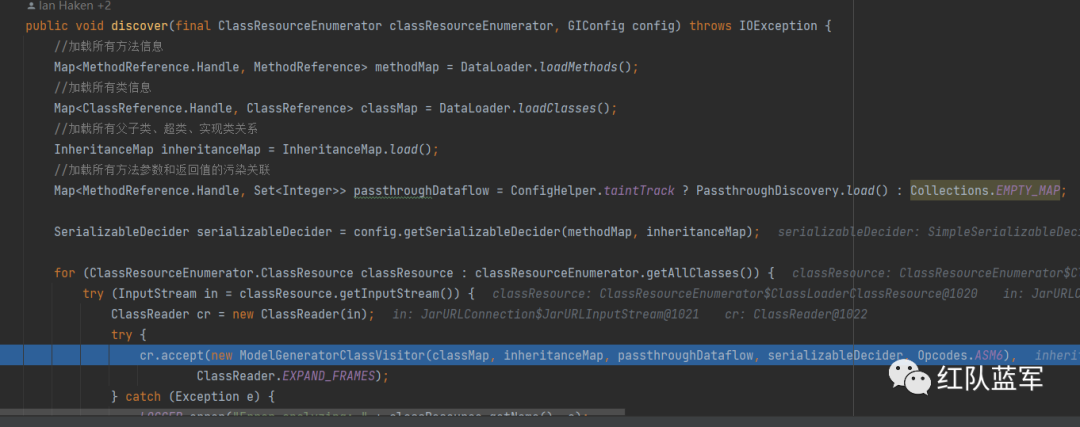
前面的三个还是和之前相同,获取类的一些相关信息,然后获取passthroughDataflow,就是上一步分析的数据(方法和返回值)
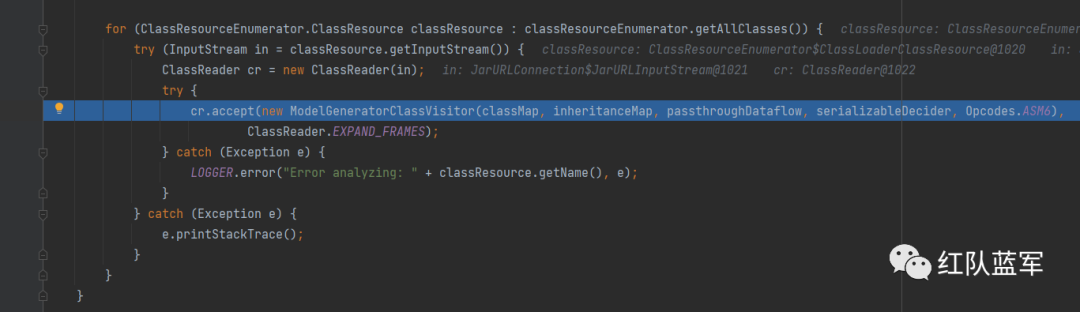
这里使用的还是观察者模式,重点就看ModelGeneratorClassVisitor#visitMethod
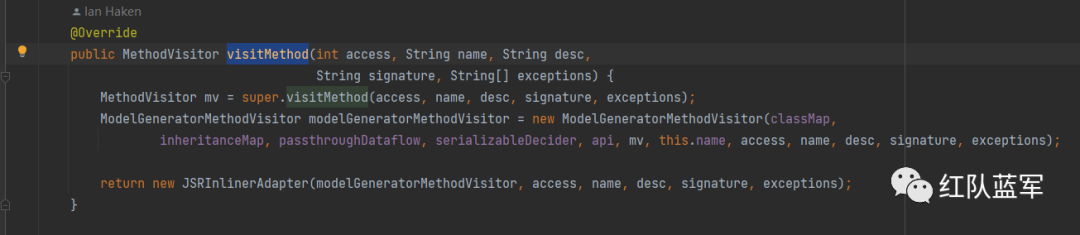
最主要用来分析的类ModelGeneratorMethodVisitor
这里还是使用上面的例子来分析,还是根据字节码指令来学习,看下和之前的区别,上面是循环方法,这里是循环.class文件
也就是先从A的构造方法开始,然后再mehod1再B这样
然后再分析方法的时候,和之前一样的,也是先执行visitCode
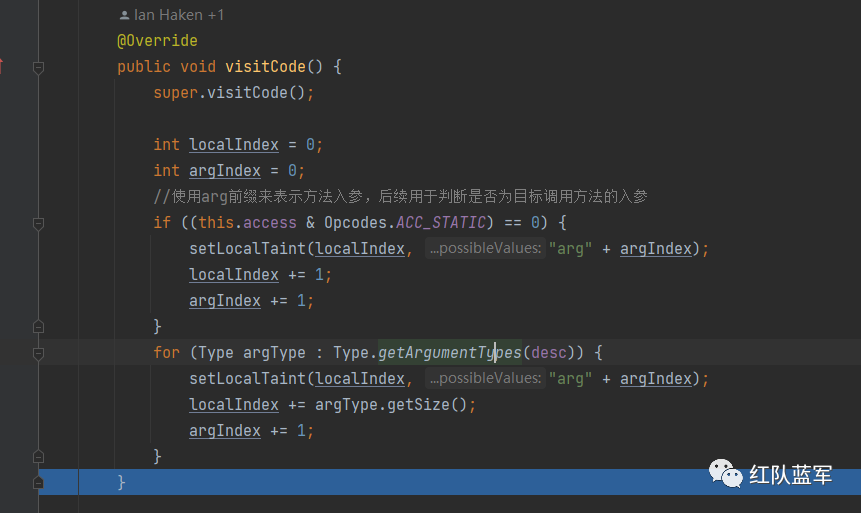
但是这里额参数和之前不太一样了,之前没有arg这个东西,先不解释为什么需要使用这样的命名方式
再执行到visitVarInsn
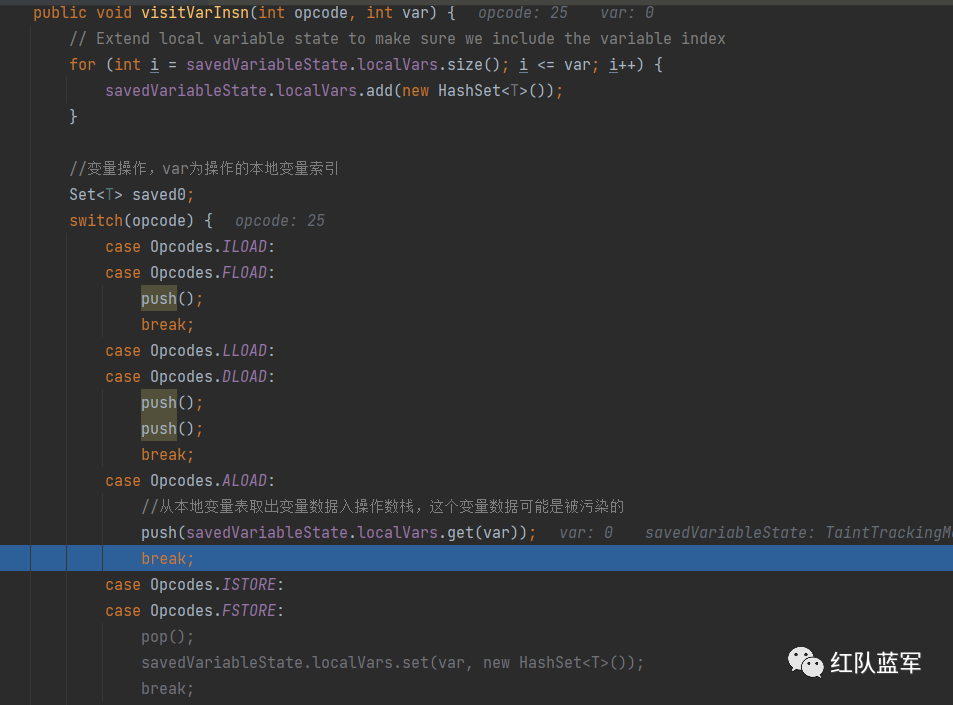
还是将数据放入操作数栈中
执行到visitMethodInsn,看看和上面有啥区别
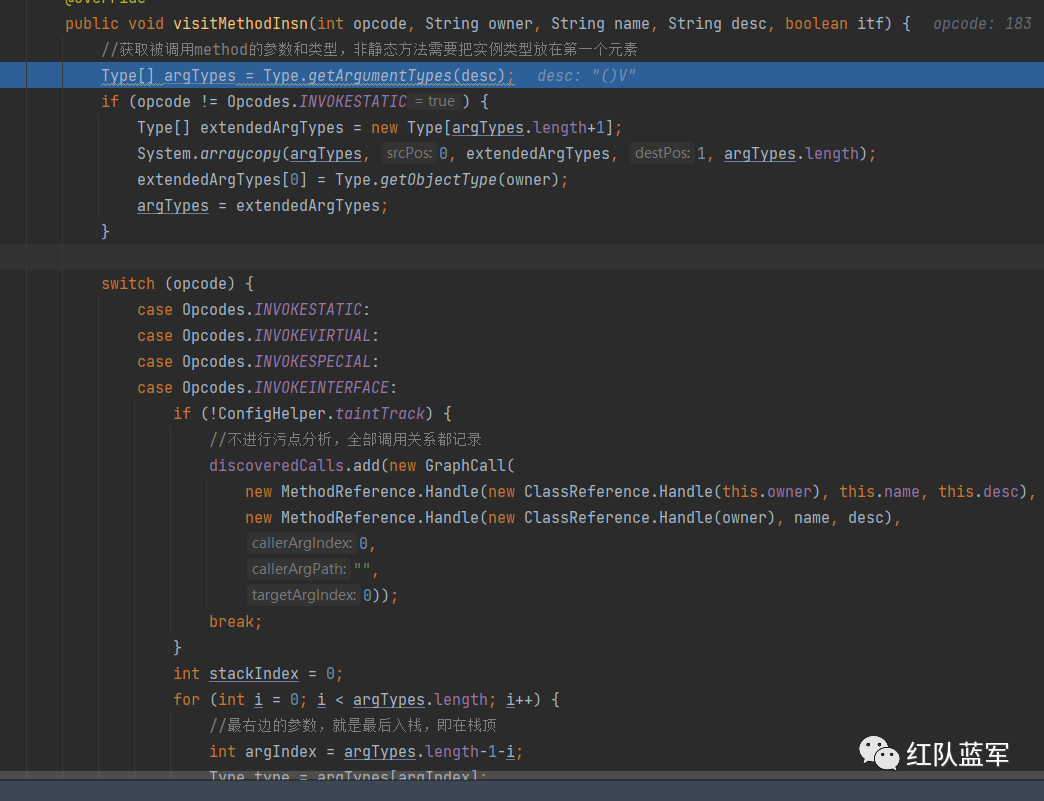
先构造argTypes,判断是否方法是否为静态的,然后往下执行,ConfigHelper.taintTrack需要手动设置,不然就一直是true
然后取出最右边的参数,即取出栈顶元素,然后判断.在哪里出现,这里判断.的原因:
-
比如我示例代码中传入的参数arg,他不是某个类的全局变量,所以就可以用arg1来表示 -
如果存在成员变量作为参数传入,比如name,那么就需要以arg0.name来表示它
然后调用
discoveredCalls.add(new GraphCall(
new MethodReference.Handle(new ClassReference.Handle(this.owner), this.name, this.desc),
new MethodReference.Handle(new ClassReference.Handle(owner), name, desc),
srcArgIndex,
srcArgPath,
argIndex))
-
new MethodReference.Handle(new ClassReference.Handle(this.owner), this.name, this.desc)调用者 -
new MethodReference.Handle(new ClassReference.Handle(owner), name, desc)被调用者 -
srcArgIndex调用者的参数位置 -
srcArgPath是否为调用者类的全局参数 -
被调用者参数的位置
形成调用者和被调用者的关系
然后进入A的下一个方法method1,因为method1里面没有什么方法的调用,所以就直接跳过了,直接看B.class的method2方法
还是一样的,改了源码之后看字节码指令
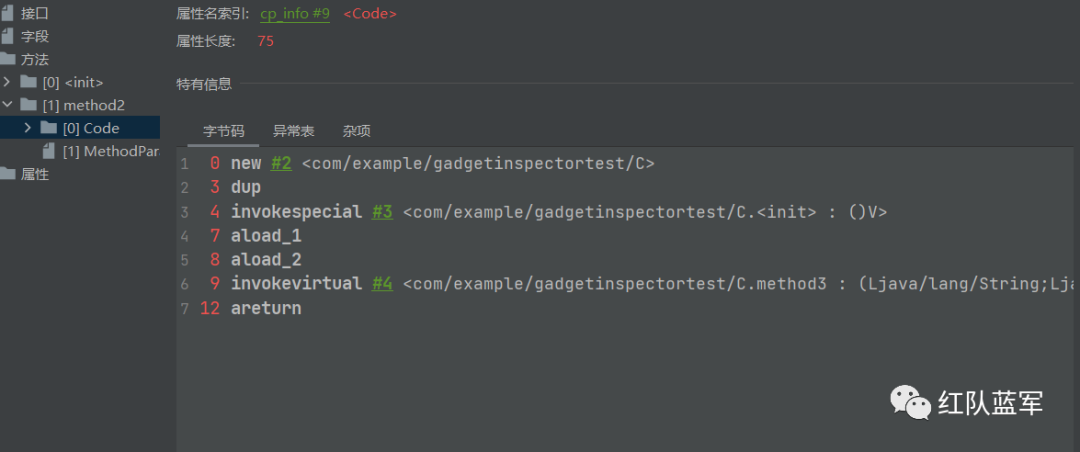
直接看调用mehod3的时候
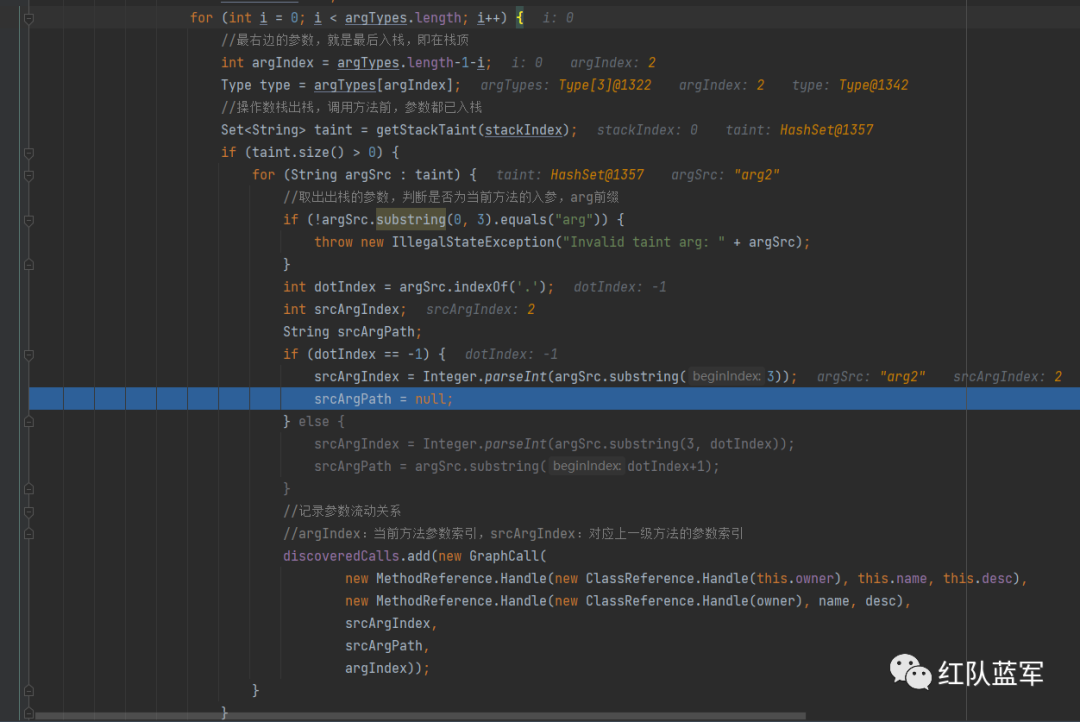
和之前的一样,,因为变量表的内容为[[arg0], [arg1], [arg2]]
先从arg2开始,形成下面的关系
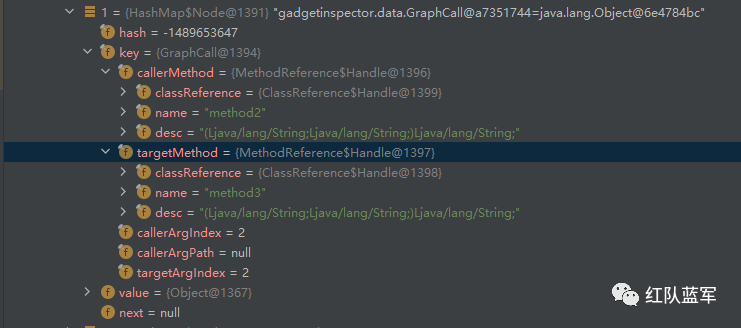
这里不知道为什么一直没有构造出arg0.name这样的形式,但是大致也可以理解为什么参数放入局部变量表和操作数栈需要加arg,因为需要用arg来区分传入的参数和被调用的传入参数之间的关系
到此gadgetinspector.CallGraphDiscovery#discover方法就结束了,调用save方法保存数据到callgraph.dat
SourceDiscovery
在SourceDiscovery类中,作者提供了一些常见的反序列化,以及其他漏洞的特征,比如原生反序列化readObject,fastjson等
在跟进sourceDiscovery.discover()中
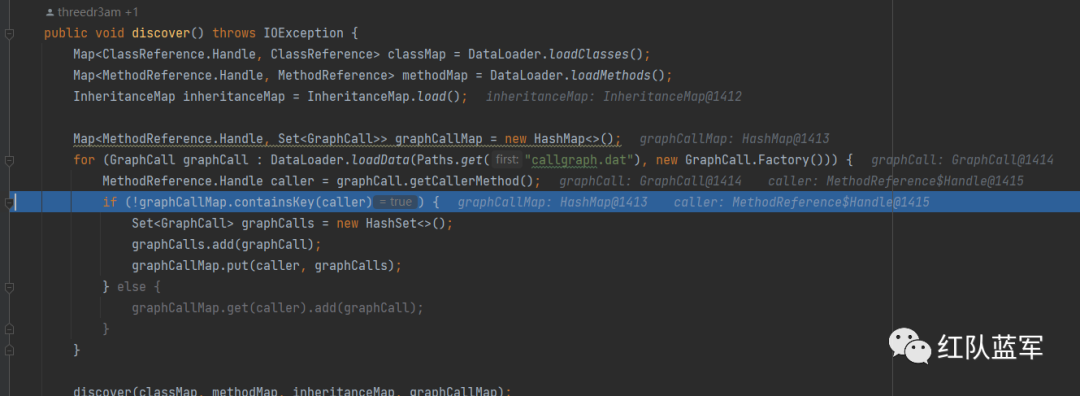
这个循环就是在组合一个graphCallMap,里面包含了调用者和graphCall(里面包含了调用者,被调用者的一些信息)的组合
然后进入discover
我这里就简单分析一下吧,修改idea的启动配置,如下:
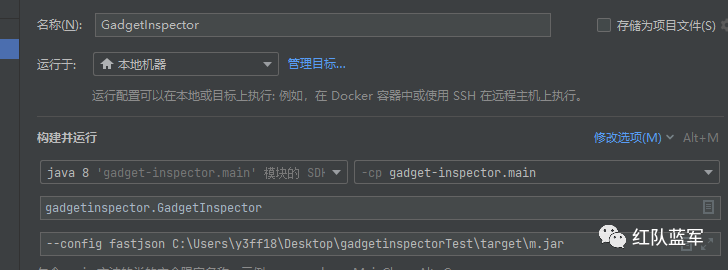
添加—config fastjson这个参数
然后进入的就是FastjsonSourceDiscovery的discover方法了
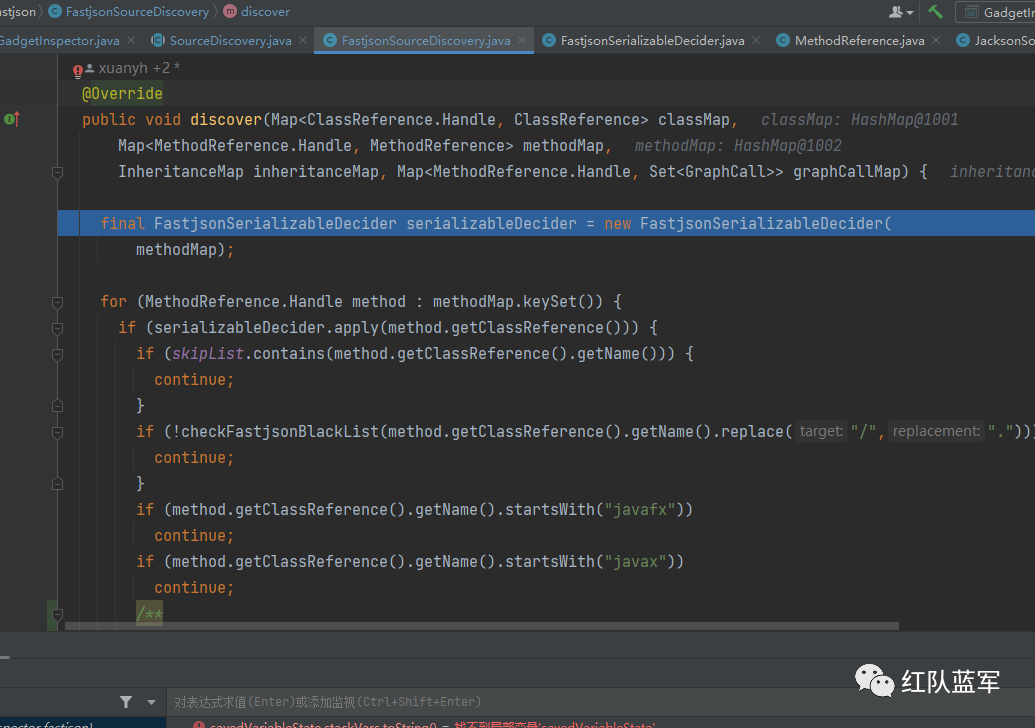
来具体看看是怎么实现的,代码比较简单
循环所有方法,判断是否在黑名单里面,是否为javax,javafx开头,checkFastjsonBlackList做了一个简单的判断,在fastjson的源码里面也有,不能[开头,并且不能再denyHashCodes黑名单里
需要满足以下条件
-
以get开头 -
get后面需要有东西,不能只为get -
参数为空 -
以set开头 -
参数为引用类型(这里使用的是正则来判断) -
并且没有返回值
如果满足以上条件,就会把方法以及污染参数的位置添加到discoveredSources中
最后save保存到sources.dat里面
GadgetChainDiscovery
在GadgetChainDiscovery类中,主要对前面获取的链子验证
进入最后的discover
gadgetChainDiscovery.discover(pathList)
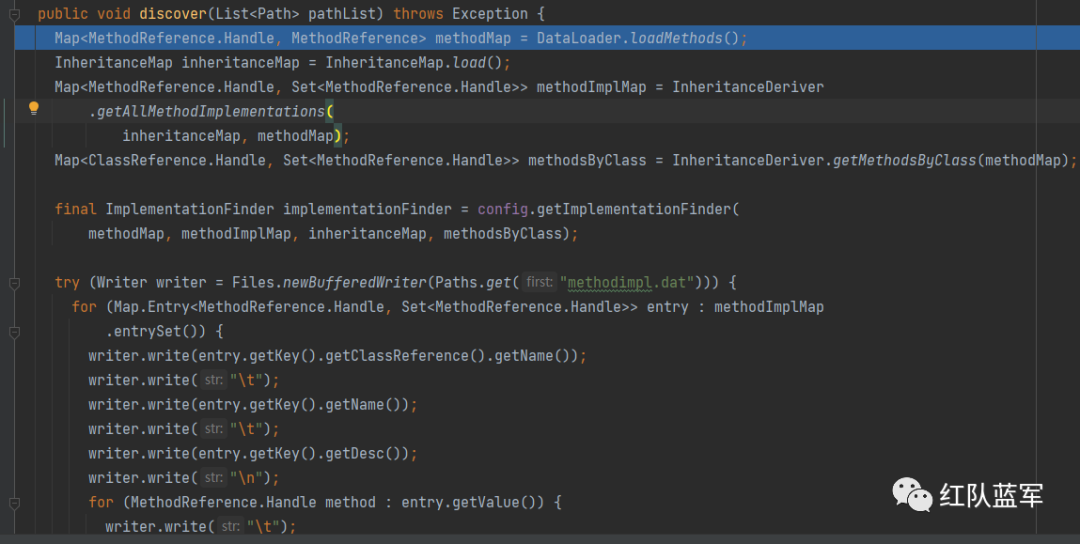
和之前的方法一样,先加载方法,父类信息
getAllMethodImplementations
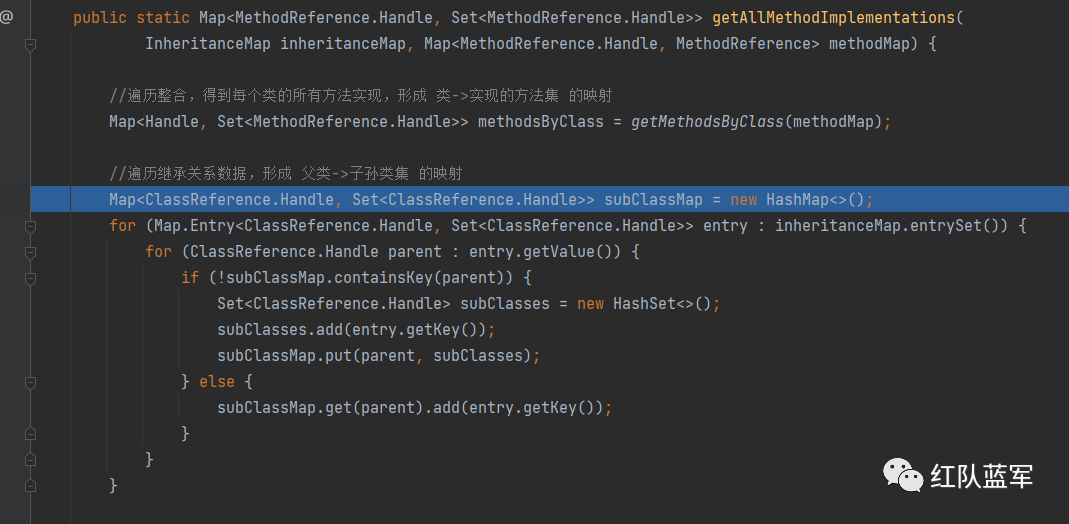
getMethodsByClass构造出一个类名对应方法的map
下面的循环构造subClassMap,父类和子类的map
for (Map.Entry<ClassReference.Handle, Set<ClassReference.Handle>> entry : inheritanceMap.entrySet()) {
for (ClassReference.Handle parent : entry.getValue()) {
if (!subClassMap.containsKey(parent)) {
Set<ClassReference.Handle> subClasses = new HashSet<>();
subClasses.add(entry.getKey());
subClassMap.put(parent, subClasses);
} else {
subClassMap.get(parent).add(entry.getKey());
}
}
}
往下
for (MethodReference method : methodMap.values()) {
// Static methods cannot be overriden
if (method.isStatic()) {
continue;
}
Set<MethodReference.Handle> overridingMethods = new HashSet<>();
Set<ClassReference.Handle> subClasses = subClassMap.get(method.getClassReference());
if (subClasses != null) {
for (ClassReference.Handle subClass : subClasses) {
// This class extends ours; see if it has a matching method
Set<MethodReference.Handle> subClassMethods = methodsByClass.get(subClass);
if (subClassMethods != null) {
for (MethodReference.Handle subClassMethod : subClassMethods) {
if (subClassMethod.getName().equals(method.getName()) && subClassMethod.getDesc().equals(method.getDesc())) {
overridingMethods.add(subClassMethod);
}
}
}
}
}
if (overridingMethods.size() > 0) {
methodImplMap.put(method.getHandle(), overridingMethods);
}
}
循环所有的方法,跳过静态方法,找到父类被子类重写的方法放入overridingMethods
然后回到discover,getMethodsByClass方法已经分析过了
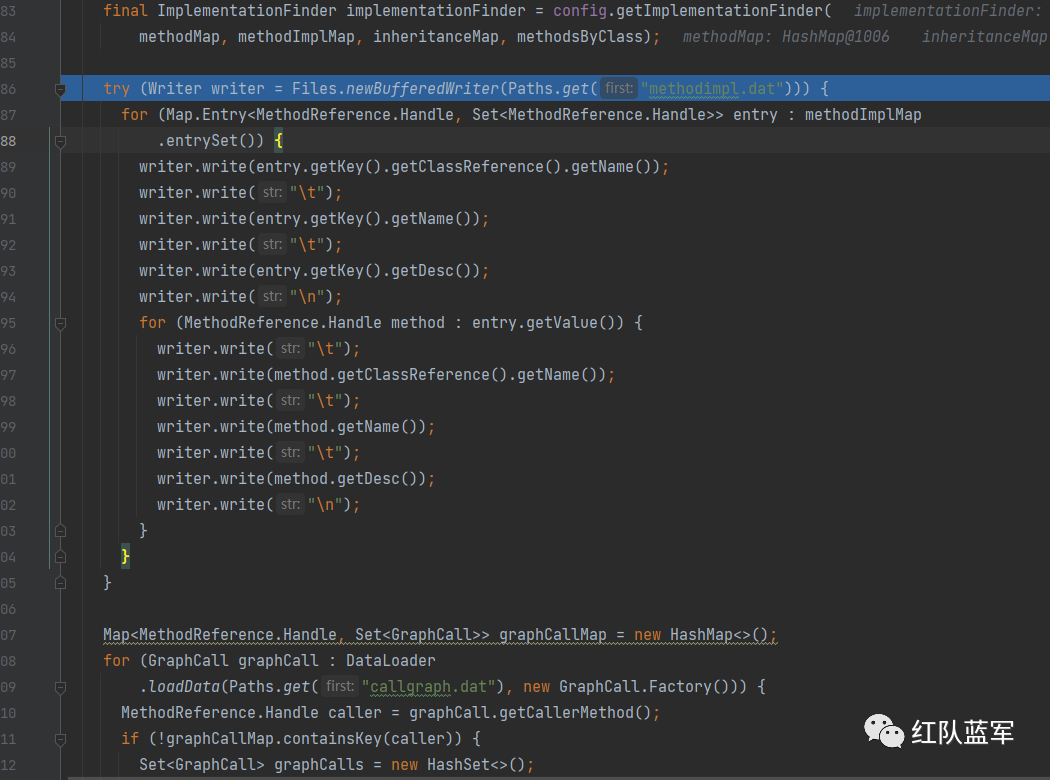
对重写的方法写入到methodimpl.dat文件中
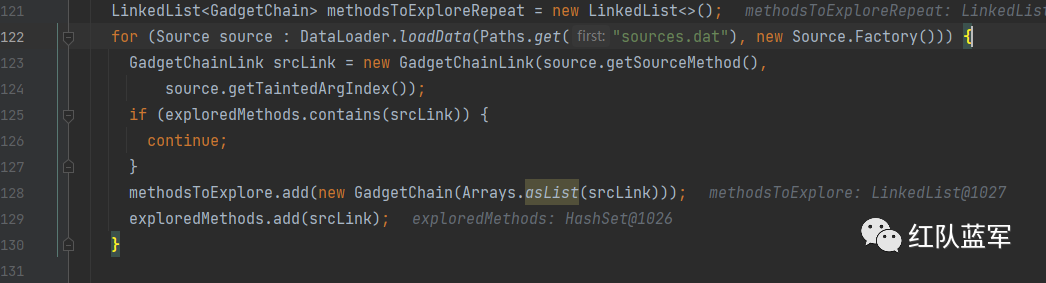
加载之前满足入口条件的方法
进入while循环
methodsToExplore.pop();将可用的链取出
chain.links.get(chain.links.size() – 1);获取链子的最后一个方法
graphCallMap.get(lastLink.method)获取最后一个方法里面调用了哪些方法
往下遍历所有这些方法,检查是否可以被污染
getImplementations获取被重写的方法
往下寻找父类中的方法
for (ClassReference.Handle parent : parents) {
Set<MethodReference.Handle> methods = methodsByClass.get(parent);
//为了解决这个bug,只能反向父类去查找方法,但是目前解决的方式可能会存在记录多个父类方法,但是已初步解决这个问题
if (methods == null)
continue;
for (MethodReference.Handle method : methods) {
if (method.getName().equals(graphCall.getTargetMethod().getName()) && method.getDesc().equals(graphCall.getTargetMethod().getDesc())) {
allImpls.add(method);
}
}
}
继续循环重写的方法
if (exploredMethods.contains(newLink)) {
if (chain.links.size() <= ConfigHelper.opLevel) {
GadgetChain newChain = new GadgetChain(chain, newLink);
methodsToExploreRepeat.add(newChain);
}
continue;
}
判断是否已经存在
if (isSink(methodImpl, graphCall.getTargetArgIndex(), inheritanceMap)) {
discoveredGadgets.add(newChain);
} else {
methodsToExplore.add(newChain);
exploredMethods.add(newLink);
}
判断是否已经到了污染方法,已经到了就表示可用,加入到discoveredGadgets中,否则继续循环
最后将可用的链子保存到文件中
isSink的代码比较简单,就不分析了
结语
整个项目到这里就结束了,陆陆续续花了不少时间,虽然gi不是主流的代码审计工具,但是通过字节码来自动审计这个思路确实挺不错的,在看这个项目的之前,建议读者先系统的学习一下asm,jvm部分需要了解字节码文件的结构以及字节码指令,这篇文件中可能也会存在一些错误,希望读者谅解。
参考链接
-
https://docs.oracle.com/javase/specs/jvms/se19/html/jvms-6.html -
https://xz.aliyun.com/t/7058#toc-5 -
https://paper.seebug.org/1034/#step4-source -
https://lsieun.github.io/java/asm/java-asm-season-01.html -
https://github.com/lsieun/learn-java-asm -
https://github.com/threedr3am/gadgetinspector
原创文章,作者:mOon,如若转载,请注明出处:https://www.moonsec.com/9296.html
