Python爬虫进阶之JS逆向(一)
【推荐学习】暗月渗透测试培训 十多年渗透经验,体系化培训渗透测试 、高效学习渗透测试,欢迎添加微信好友aptimeok 咨询。
前言
最近有朋友推荐了一个很简单的需要 js 逆向的网站
中国土地市场网
主要是需要获取下面的信息
上面是用代码请求返回的响应
html 中嵌入了 JS,而且很可能做了跳转,因为有个 location 的变量
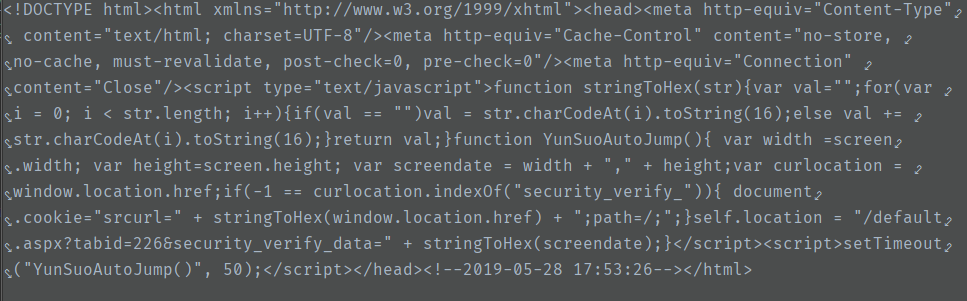

破解
下面是通过 Chrome 浏览器抓包的过程
经过了两次跳转
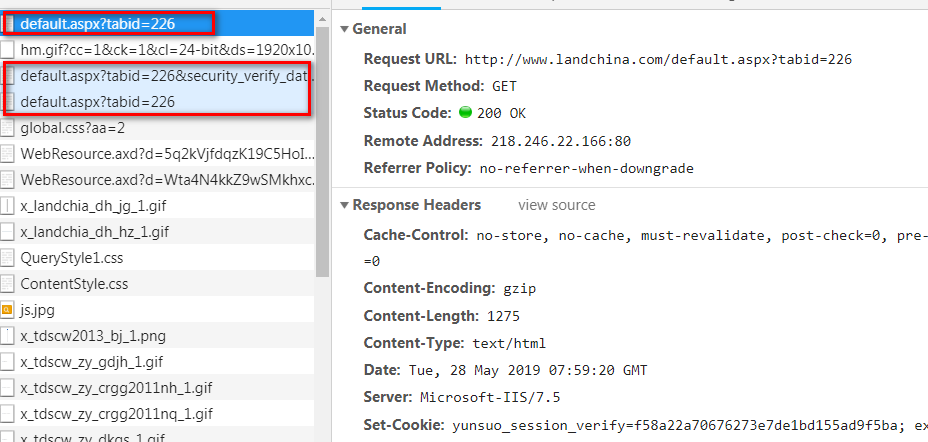
其中重定向的链接是在第一次请求返回的响应里面,用 JS 生成的

so, 我们将返回的 JS 扣出来,在本地调试下
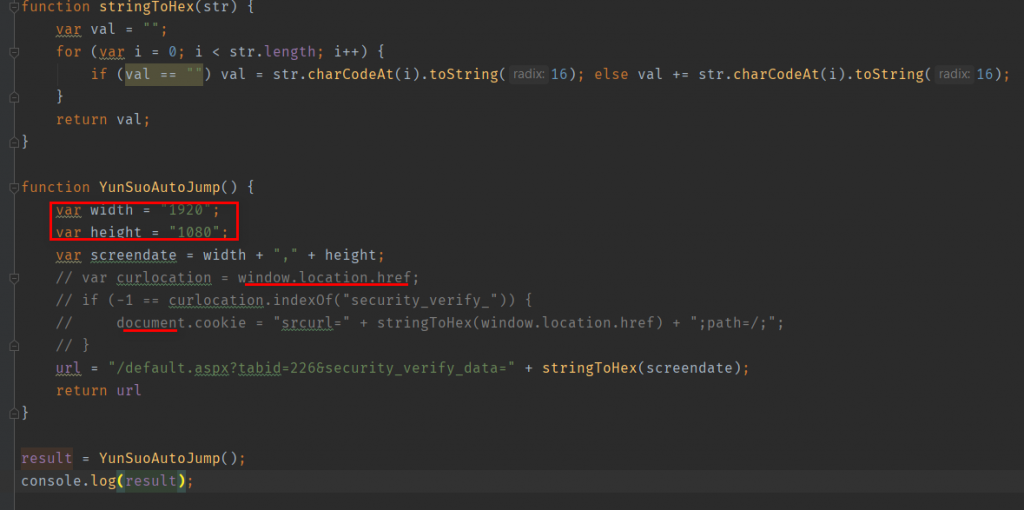
其中有些用不到的参数,直接注释掉
比如参数 curlocation 是当前页面的 href,没有用到,反而会给我们调试增加阻碍
因为我们没有 window 这个对象
运行这段 JS,直接生成我们所需的参数
验证
从抓包中我们可以得知总共有三次清求
其中第一次和第二次都会生成验证的 cookie
所以我们也用代码模拟三次请求
代码如下:
def spider():
response = session.get(url)
text = response.text
# f_js = re.findall("javascript\">(.*?)</script>", text)[0]
ctx = execjs.compile(js)
location = ctx.call("YunSuoAutoJump")
second_url = "http://www.landchina.com" + location
_ = session.get(second_url)
res = session.get(url)
selector = Selector(text=res)
result = selector.css("#TAB_contentTable tr")[1:]
td_list = result.css("td")
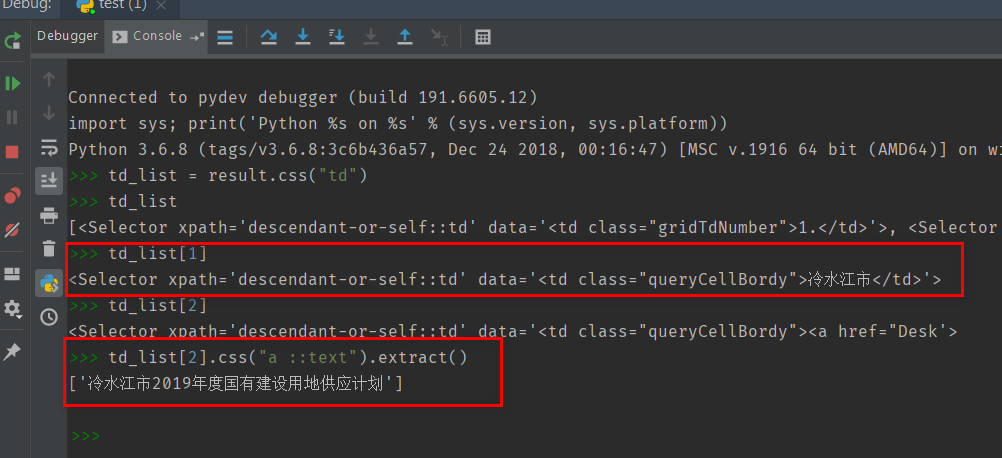
最后我们看下能否提取出数据
结果一目了然!
本文来自https://www.jianshu.com/p/9abe5f713ed6,经授权后发布,本文观点不代表立场,转载请联系原作者。
赞 (0)
Android逆向实战篇(加密数据包破解)
« 上一篇
2020年5月31日 pm3:26
Python爬虫进阶之JS逆向混淆加密和AES加密的破解
下一篇 »
2020年5月31日 pm4:05
